南京大学ics2019_PA5
PA5实验报告
2013599 田佳业
实现浮点指令
先看一下目前进入战斗场面是什么情况。这里有一个问题是怎么进入战斗场面。因为现在仙剑奇侠传跑的比较慢,这一步都费了挺长时间(笑)
首先进入主界面选旧的回忆,读最后一个档(倒数第二个档试过没有怪),进去走迷宫,上下左右移动,走一会儿遇到怪物,自动进入战斗场景。往右下角走会快一些。怪物画的好涩

按照指导书,修改
navy-apps/apps/pal/src/FLOAT/FLOAT.c和对应的头文件。
根据讲义:
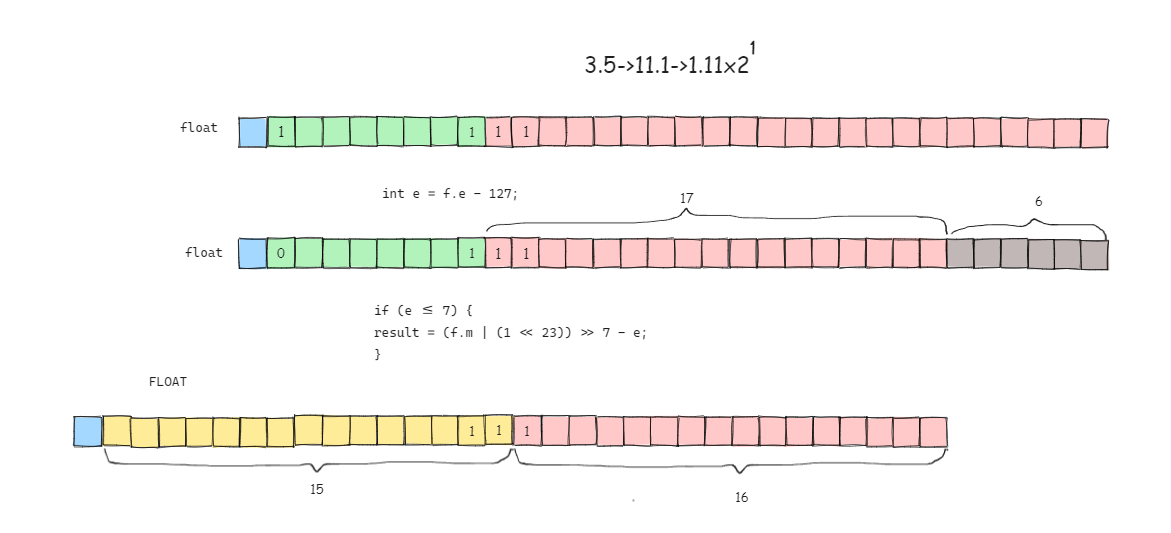
我们先来说明如何用一个32位整数来表示一个实数. 为了方便叙述, 我们称用binary scaling方法表示的实数的类型为
FLOAT. 我们约定最高位为符号位, 接下来的15位表示整数部分, 低16位表示小数部分, 即约定小数点在第15和第16位之间(从第0位开始). 从这个约定可以看到,FLOAT类型其实是实数的一种定点表示.asciidoc31 30 16 0 +----+-------------------+--------------------+ |sign| integer | fraction | +----+-------------------+--------------------+
相应的,IEEE754的标准,图源

这一部分有点像CSAPP的DataLab,但是由于使用定点表示实数的场景越来越少,这一部分实际价值也并不大。可以看到后面版本的PA已经将这一部分去除。
浮点转定点
先考虑浮点转定点。
C
typedef int FLOAT;
FLOAT f2F(float a) {
union float_ {
struct {
uint32_t m : 23;
uint32_t e : 8;
uint32_t signal : 1;
};
uint32_t value;
};
union float_ f;
f.value = *((uint32_t*)(void*)&a);
int e = f.e - 127;
FLOAT result;
if (e <= 7) {
result = (f.m | (1 << 23)) >> 7 - e;
}
else {
result = (f.m | (1 << 23)) << (e - 7);
}
return f.signal == 0 ? result : (result|(1<<31));
}浮点乘除
乘法
整数部分和小数部分分别相乘,进位。关于舍入处理,这里是采用的“0舍1入”的模式。
C++
FLOAT F_mul_F(FLOAT a, FLOAT b) {
int sign = (a ^ b) >> 31; // 计算符号位
// 将a和b的符号位清零
a = a & 0x7FFFFFFF;
b = b & 0x7FFFFFFF;
// 执行乘法运算
int product_hi = (a >> 16) * (b >> 16); // 高16位的乘积
int product_lo = (a & 0xFFFF) * (b & 0xFFFF); // 低16位的乘积
// 处理溢出
int carry = product_lo >> 16; // 检查低16位乘积是否产生进位
product_hi += carry; // 加上进位
// 舍入处理
int rounding = 0x8000; // 用于舍入的值
int result = (product_hi << 16) + ((product_lo + rounding) >> 16);
// 恢复符号位
result = (result ^ sign) - sign;
return result;
}除法
和乘法类似,也是采用列竖式的思路。
C++
FLOAT F_div_F(FLOAT a, FLOAT b) {
FLOAT result = Fabs(a) / Fabs(b);
FLOAT m = Fabs(a);
FLOAT n = Fabs(b);
m = m % n;
//竖式除法
for (int i = 0; i < 16; i++) {
m <<= 1;
result <<= 1;
if (m >= n) {
m -= n;
result++;
}
}
//恢复符号位
if (((a ^ b) & 0x80000000) == 0x80000000) {
result = -result;
}
return result;
}FLOAT和int转换
直接取整数部分即可。
C++
static inline int F2int(FLOAT a)
{
if ((a & 0x80000000) == 0)
{
return a >> 16;
}
else
{
return -((-a) >> 16);
}
}
static inline FLOAT int2F(int a)
{
if ((a & 0x80000000) == 0)
{
return a << 16;
}
else
{
return -((-a) << 16);
}
}FLOAT和int乘除
直观的思路是都把他们转成FLOAT类型。
C++
static inline FLOAT F_mul_int(FLOAT a, int b)
{
// assert(0);
return F_mul_F(a, int2F(b));
}
static inline FLOAT F_div_int(FLOAT a, int b)
{
// assert(0);
return F_div_F(a, int2F(b));
}成功运行战斗场景。
通往高速的次元
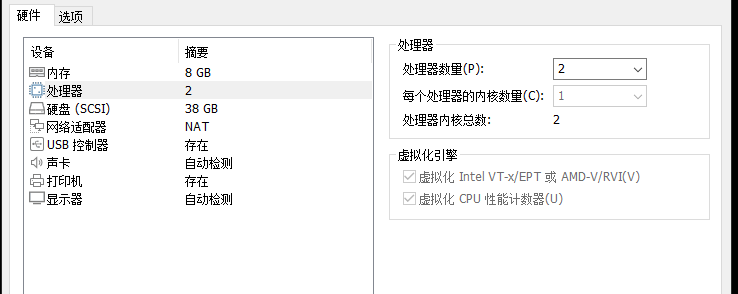
如果用VMware的话需要开这两个选项:
报这种错误:
shell
Error:
You may not have permission to collect stats.
Consider tweaking /proc/sys/kernel/perf_event_paranoid:
-1 - Not paranoid at all
0 - Disallow raw tracepoint access for unpriv
1 - Disallow cpu events for unpriv
2 - Disallow kernel profiling for unpriv可以临时提权:
shell
sudo sh -c "echo -1 > /proc/sys/kernel/perf_event_paranoid"运行:
shell
perf record nemu/build/x86-nemu nanos-lite/build/nanos-lite-x86-nemu.bin我感觉也不太好看出什么。。
好吧,下一章第一句话就是
相信你也已经在NEMU中运行过
microbench, 发现NEMU的性能连真机的1%都不到. 使用perf也没有发现能突破性能瓶颈的地方.
性能瓶颈的来源
略
南京大学ics2019_PA5
http://lunaticsky-tql.github.io/posts/27788/