南京大学ics2019_PA1
PA1实验报告
田佳业 2013599
为了方便VSCode远程连接,采用64位Ubuntu系统完成ics2019对应的PA。因此报告中一部分代码可能会与2018版本不一致。
PA1.1
任务:实现单步执行, 打印寄存器状态, 扫描内存
开天辟地的篇章
任务
这一部分介绍了“最简单的计算机”应当具有哪些特征和功能。
思考题
计算机可以没有寄存器吗?
存储层次的产生是顺应规律的,我们会自然的把经常访问的数据放在更快的,离CPU更近(更容易获取)的存储介质上。假设计算机“不得不”没有寄存器, 我们也会让内存充当”寄存器“的作用(相比磁盘等更慢的介质),只不过这样会使得性能变差, 因为一些需要经常使用的数据也不得不放在内存当中.
计算机的状态模型与图灵机的关系?
对于TRM来说, 是不是也有这样状态的概念呢? 具体地, 什么东西表征了TRM的状态? 在状态模型中, 执行指令和执行程序, 其本质分别是什么?
图灵机中“状态”的概念在PA中体现在
NEMUState这个结构中。包括{ NEMU_STOP, NEMU_RUNNING, NEMU_END, NEMU_ABORT },图灵机中”格局“的概念(包括带描述,当前状态和读写头)对应到计算机就像”快照“,分别对应存储器中内容,计算机运行状态和程序计数器。图灵机中输入和转移函数都从”纸带“中获取,就像冯诺依曼体系结构,执行指令和执行程序本质上没有什么区别。
RTFSC
任务
实现x86的寄存器结构体
这一部分讲义中有答案,在此不再列出代码。匿名union可以在共享内存的同时,还能以union内的名称在外部访问。这也适应了PA中”寄存器别名“的需求。
reg_test0是如何测试你的实现的?
代码中的
assert()条件是根据什么写出来的: 产生随机值到sample数组,让cpu获取,检查是否cpu能够正确获取这些值。ps:通过与1与可以取低位。
void reg_test() {
//init random seed
srand(time(0));
uint32_t sample[8];
//generate random values for eip
uint32_t eip_sample = rand();
cpu.eip = eip_sample;
int i;
//generate random values for general registers
for (i = R_EAX; i <= R_EDI; i ++) {
sample[i] = rand();
reg_l(i) = sample[i];
// test whether reg_w() can normally return the low 16 bits of the general register
assert(reg_w(i) == (sample[i] & 0xffff));
}
// test whether reg_w() can normally return the low 8 bits of the general register
assert(reg_b(R_AL) == (sample[R_EAX] & 0xff));
assert(reg_b(R_AH) == ((sample[R_EAX] >> 8) & 0xff));
assert(reg_b(R_BL) == (sample[R_EBX] & 0xff));
assert(reg_b(R_BH) == ((sample[R_EBX] >> 8) & 0xff));
assert(reg_b(R_CL) == (sample[R_ECX] & 0xff));
assert(reg_b(R_CH) == ((sample[R_ECX] >> 8) & 0xff));
assert(reg_b(R_DL) == (sample[R_EDX] & 0xff));
assert(reg_b(R_DH) == ((sample[R_EDX] >> 8) & 0xff));
// test the alias of general registers
assert(sample[R_EAX] == cpu.eax);
assert(sample[R_ECX] == cpu.ecx);
assert(sample[R_EDX] == cpu.edx);
assert(sample[R_EBX] == cpu.ebx);
assert(sample[R_ESP] == cpu.esp);
assert(sample[R_EBP] == cpu.ebp);
assert(sample[R_ESI] == cpu.esi);
assert(sample[R_EDI] == cpu.edi);
assert(eip_sample == cpu.eip);
}究竟要执行多久?
在cmd_c()函数中,
调用cpu_exec()的时候传入了参数-1的含义?
-1的十六进制表示就是0xffffffff, 然后这是一个无符号的类型, 所以是最大的无符号数, 所以在正常情况下(nemu_state.state == NEMU_RUNNING)会一直执行下去。在for循环内,2018版的PA为exec_wrapper,2019PA为exec_once就做了图灵机章节中所述三件基本事情:取指,执行,更新PC。
潜在的威胁
"调用cpu_exec()的时候传入了参数-1",
这一做法属于未定义行为吗? 请查阅C99手册确认你的想法.
C99的文档并不太好找,但猜测既然这么问,很可能是属于未定义行为。
温故而知新
opcode_table到底是个什么类型的数组?
OpcodeEntry类型。定义如下:
typedef struct {
DHelper decode;
EHelper execute;
int width;
} OpcodeEntry;有始有终
对于GNU/Linux上的一个程序, 怎么样才算开始? 怎么样才算是结束? 对于在NEMU中运行的程序, 问题的答案又是什么呢?
NEMU中为什么要有
nemu_trap? 为什么要有monitor?在GNU/Linux上的一个C程序,main函数只是充当一个”入口“的作用,在main函数调用之前,为了保证程序可以顺利进行,要先初始化进程执行环境,如堆分配初始化、线程子系统等,如果是C++,C++的全局对象构造函数也是这一时期被执行的,全局析构函数是main之后执行的。
Linux一般程序的入口是__start函数,有两个段:
- .init段:进程的初始化代码,一个程序开始运行时,在main函数调用之前,会先运行.init段中的代码。
- .fini段:进程终止代码,当main函数正常退出后,glibc会安排执行该段代码。
在NEMU中
nemu_trap指令, 就是让程序来结束运行的。定义一个结束程序的API, 比如void halt(), 它对不同架构上程序的不同结束方式进行了抽象: 程序只要调用halt()就可以结束运行。
基础设施
任务
这一部分主要是需要实现一个简易调试器,在nemu/src/monitor/debug/ui.c中仿照给出的命令可以比较容易的完成,并没有遇到比较大的困难。
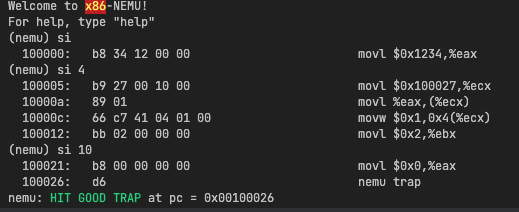
单步执行
如果给出参数,执行指定步数,没有,执行一步。读取si后面的数字可以用*args参数,当然根据文档提示也可以用strtok。下面两种实现方式都是可以的。注意用strtok时由于在ui_mainloop中已经传入的str,根据strtok是使用方式后续第一和参数应当使用NULL。
static int cmd_si(char *args) {
int step = 1;
if (args != NULL) {
sscanf(args, "%d", &step);
}
cpu_exec(step);
return 0;
}static int cmd_si(char *args){
char * step_c= strtok(NULL, " ");
if(step_c == NULL){
cpu_exec(1);
}
else{
int step = atoi(step_c);
cpu_exec(step);
}
return 0;
}
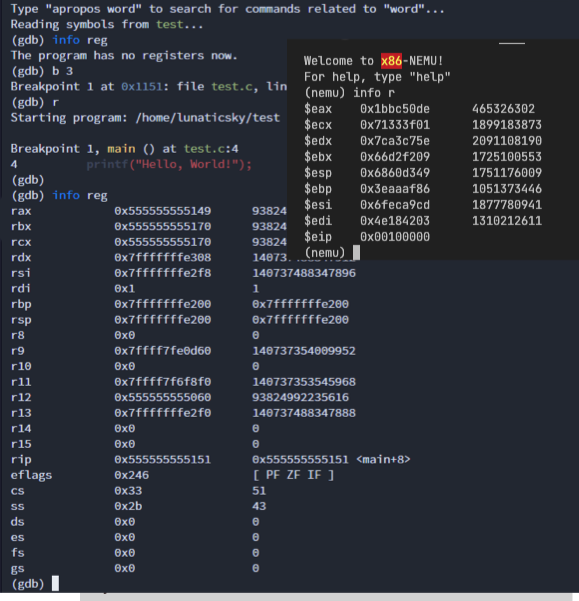
打印寄存器
201版本的PA针对不同体系结构的寄存器读取做了抽象,因此在cmd_info中调用isa_reg_display,具体工作在这个函数中进行。
对于x86实现如下,仿照了gdb的格式,输出寄存器,二进制和十进制值。
void isa_reg_display()
{
// it works like the gdb command "info reg"
for (int i = R_EAX; i <= R_EDI; i++)
{
printf("$%s\t0x%08x\t%d\n", regsl[i], reg_l(i), reg_l(i));
}
//print pc
printf("$eip\t0x%08x\n", cpu.pc);
}
实现扫描内存
这一部分也比较容易,使用用sscanf读取参数,并调用isa_vaddr_read进行读取即可。代码不再赘述。
问题
基础设施-提高项目开发的效率
现在我们来假设我们没有提供一键编译的功能,你需要通过手动键入 gcc 命令的方式来编译源文件:假 设你手动输入一条 gcc 命令需要 10 秒的时间(你还需要输入很多编译选项,能用 10 秒输入完已经是非常快的了), 而 NEMU 工程下有 30 个源文件,为了编译出 NEMU 的可执行文件,你需要花费多少时间?然而你还需要在开发 NEMU 的过程中不断进行编译,假设你需要编译 500 次 NEMU 才能完成 PA,一学期下来,你仅仅花在键入编译命令上的时间有多少?
需要15000s的时间。因此虽然make的语法显得非常晦涩,但和其他GNU工具链一样,当充分熟悉之后可以极大提高开发效率。
如何测试字符串处理函数?
你可以考虑一下, 你会如何测试自己编写的字符串处理函数?
可以像表达式求值一样的思路。如果有已知的库函数能够解决问题,可以通过编写测试用例对照测试。如果没有,可以尝试使用不同的方式实现,进行对照。但这会受到已有思路的限制。当然,最基础的断言,打断点等调试手段也会有帮助,
好像有点不对劲
和默认镜像进行对比的时候, 扫描内存的结果貌似有点不太一样. 你知道这是为什么吗?
2019版的这个问题,现在还不是很明白,不过猜测与内存地址转换有关系。
PA1.2
表达式求值
任务
完成表达式求值的功能。在编译原理的词法分析部分已经有所基础,但在实际编码的过程中尽管也查阅的网上很多资料,写起来也并不太顺手,也是整个实验中耗时最长的一部分。不过有前人的铺垫结合自己的的理解,测试的过程总体还算顺利,所幸没有遇到太奇怪的bug。
测试程序
在写这一周目部分代码之前先做的是测试部分(==后面发现2018的PA并没有要求实现这一部分(捂脸))。测试部分如文档所述非常巧妙,生成随机的数字和操作符,然后写了一个模版c程序把表达式通过sprintf”嵌入“到代码中最后使用系统命令编译运行这个C程序。这一部分可以详见nemu/tools/gen-expr/gen-expr.c部分。不过递归的实现还有些小问题,比如连续生成数字或运算结果过大导致结果溢出int范围等。最后还是从里面找了一些正常的表达式手动输入进行测试的。
添加正则
编译原理课这一块已经很熟悉了。其中寄存器可以采用宽松验证和准确验证。对于debugger来说准确验证更好,还是尽量避免未知行为的发生。
// {"\\$[a-zA-Z]+",TK_REG}, //register
// more specific
{"\\$(e[abcd]x|e[sbi]p|e[ds]i|[abcd]x|[sb]p|[ds]i)", TK_REG}};make_token
添加完规则后,框架中已经给出了match的过程,我们只需要把匹配到的token信息保存下来即可。
预处理
在进入求值部分之前,为了区分负数和减号以及解引用和乘号,按照讲义的思路先过一遍预处理。一个坑是判断是数字的时候不要忘了有十六进制数的存在。这个小问题是写eval函数处理十六进制数的时候想起来的。
uint32_t expr(char *e, bool *success)
{
if (!make_token(e))
{
*success = false;
return 0;
}
/* TODO: Insert codes to evaluate the expression. */
// handle the deref and neg at the first
// because if the * or - is at the first, it must be unary operator
// pre-processing
if (tokens[0].type == '-')
{
tokens[0].type = TK_DEREF;
}
else if (tokens[0].type == '*')
{
tokens[0].type = TK_DEREF;
}
// parse the rest tokens
for (int i = 1; i < nr_token; i++)
{
if (tokens[i].type == '-')
{
if (tokens[i - 1].type != TK_NUM && tokens[i - 1].type != TK_HEXNUM && tokens[i - 1].type != TK_REG && tokens[i - 1].type != ')')
{
tokens[i].type = TK_NEG;
}
}
else if (tokens[i].type == '*')
{
if (tokens[i - 1].type != TK_NUM && tokens[i - 1].type != TK_HEXNUM && tokens[i - 1].type != TK_REG && tokens[i - 1].type != ')')
{
tokens[i].type = TK_DEREF;
}
}
}
*success = true;
return eval(0, nr_token - 1);
// return 0;
}eval递归求值
这一部分是这个任务的核心,讲义中也给出了实现的思路。我的实现代码如下:
uint32_t eval(int p, int q)
{
if (p > q)
{
/* Bad expression */
panic("Bad expression");
return 0;
}
else if (p == q)
{
switch (tokens[p].type)
{
case TK_NUM:
return atoi(tokens[p].str);
case TK_HEXNUM:
return strtol(tokens[p].str, NULL, 16);
case TK_REG:;
// remove the $ in the string
char *reg_name = tokens[p].str + 1;
for (int i = R_EAX; i < R_EDI; i++)
{
if (strcmp(reg_name, m_regsl[i]) == 0)
{
return reg_l(i);
}
if (strcmp(reg_name, m_regsw[i]) == 0)
{
return reg_w(i);
}
if (strcmp(reg_name, m_regsb[i]) == 0)
{
return reg_b(i);
}
}
if (strcmp(tokens[p].str, "$eip") == 0)
{
return cpu.pc;
}
else
{
printf("error in TK_REG in eval()\n");
assert(0);
}
}
}
else if (check_parentheses(p, q) == true)
{
/* The expression is surrounded by a matched pair of parentheses.
* If that is the case, just throw away the parentheses.
*/
return eval(p + 1, q - 1);
}
else
{
int op_pos = get_domin_op_pos(p, q);
// printf("op_pos=%d\n", op_pos);
uint32_t val2 = eval(op_pos + 1, q);
// printf("p=%d\n", p);
if (op_pos == p)
{
switch (tokens[op_pos].type)
{
case TK_DEREF:
return vaddr_read(val2, 4);
case TK_NEG:
return -val2;
case TK_NOT:
return !val2;
default:
panic("unrecognized single operator in eval()");
}
}
uint32_t val1 = eval(p, op_pos - 1);
switch (tokens[op_pos].type)
{
case '+':
return val1 + val2;
case '-':
return val1 - val2;
case '*':
return val1 * val2;
case '/':
return val1 / val2;
case TK_AND:
return val1 && val2;
case TK_OR:
return val1 || val2;
case TK_EQ:
return val1 == val2;
case TK_NEQ:
return val1 != val2;
default:
panic("unrecognized operator in eval()");
}
}
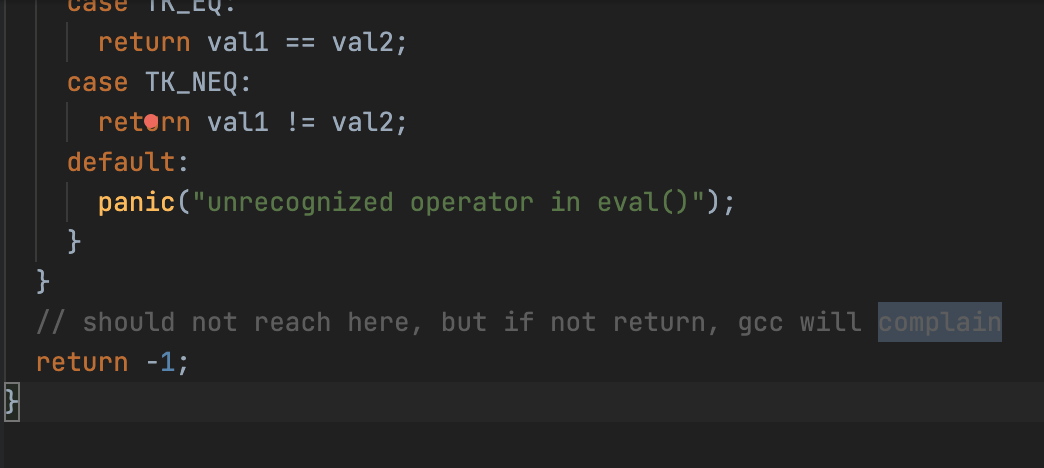
// should not reach here, but if not return, gcc will complain
return -1;
}最后求值的时候,if (op_pos == p)条件可以使单目运算优先被处理,这一点也是参照了网上的代码才想到。
其中check_parentheses(p, q)部分的实现不复杂,扫一遍就可以了。先判断左右两端是否被括号包围,再判断里面的括号是否匹配。这一部分代码较简单,不再赘述。
获取优先级部分比较复杂,又回到了被编译原理支配的痛苦。
int get_domin_op_pos(int p, int q)
{
int bracket_cnt = 0;
// level 0: * - !
// level 1: * /
// level 2: + -
// level 3: &&
// level 4: ||
// level 5: == !=
int levels[6] = {-1, -1, -1, -1, -1, -1};
for (int i = p; i < q; i++)
{
if (tokens[i].type == '(')
{
bracket_cnt++;
}
if (tokens[i].type == ')')
{
bracket_cnt--;
}
if (bracket_cnt == 0)
{
switch (tokens[i].type)
{
case TK_DEREF:
case TK_NEG:
case TK_NOT:
if (levels[0] == -1)
{
levels[0] = i;
}
break;
case '*':
case '/':
levels[1] = i;
break;
case '+':
case '-':
levels[2] = i;
break;
case TK_AND:
levels[3] = i;
break;
case TK_OR:
levels[4] = i;
break;
case TK_EQ:
case TK_NEQ:
levels[5] = i;
break;
}
}
}一个坑是注意到讲义中提到出现在一对括号中的token不是主运算符,因此一定要确保只对括号外的运算符判断优先级即可。优先级参照C++的优先级表分成了六个等级,依次扫描即可。
接下来for循环遍历的过程自然地返回了存在的最高优先级运算符的位置。
for (int i = 0; i < 6; i++)
{
if (levels[i] != -1)
{
return levels[i];
}
}
// if no operator found
printf("error:no operator found in get_domin_op_pos\n");
panic("p=%d,q=%d in get_domin_op_pos() where got no token", p, q);
}当然最后需要在ui.c加入表达式求值的指令。
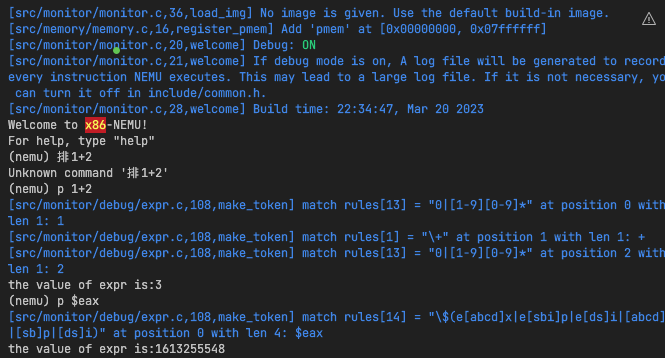
实现效果:
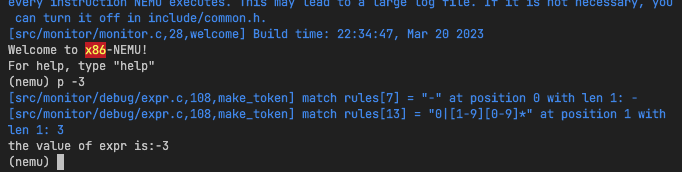
感想
在表达式求值的实验中确实感受到了基本调试工具和手段的重要性。首先gcc开启--Wall和-Werror能够杜绝绝大多数“手误”(第一次完整实现完表达式求值的时候错误爆满屏..),同时不同位置的assert也便于查看问题出现的位置。
PA1.3
监视点
任务
这一部分相比前两部分要简单很多。主要是链表的基本操作,操作系统,编译原理中也经过多次练习。主要是需要考虑清楚清楚是“头插法”还是“尾插法”。
先在nemu/include/monitor/watchpoint.h中完成对结构体 的补充和函数的定义。
typedef struct watchpoint
{
int NO;
struct watchpoint *next;
/* TODO: Add more members if necessary */
char expr[32];
uint32_t value;
} WP;当我们需要打印断点信息的时候需要知道表达式和具体值。
添加监视点需要从free链表中取一个结点给head
链表,且将表达式、节点值赋给它,最后返回该节点的编号。删除监视点是遍历head链表直到找出对应NO的结点,从head中删除,添加到free链表中。同时
修改类型、表达式、值。代码参见nemu/src/monitor/debug/watchpoint.c,不再赘述。
问题
下面的问题的答案都主要来自于讲义中提供的文章,这篇文章比较深入的介绍了x86 int3指令的工作方式。
一点也不能长?
我们知道 int3 指令不带任何操作数,操作码为 1 个字节,因此指令的长度是 1 个字节.这是必须的吗?假设有 一种 x86 体系结构的变种 my-x86,除了 int3 指令的长度变成了 2 个字节之外,其余指令和 x86 相同.在 my-x86 中,文章中的断点机制还可以正常工作吗?为什么?
Intel Mannual 原文中提到:
This one byte form is valuable because it can be used to replace the first byte of any instruction with a breakpoint, including other one byte instructions, without over-writing other code
第二个问题的答案是不能。
文章中还给出了这个例子:
assembly.. some code .. jz foo dec eax >foo: call bar .. some code ..假设我们想在dec-eax上放置一个断点。这恰好是一条单字节指令(操作码为0x48)。如果替换断点指令的长度超过1字节,将被迫覆盖下一条指令(调用)的一部分,这将使其混乱,并可能产生完全无效的内容。并且我们不确定
jz foo会不会跳转。在不停止dec-eax的情况下,CPU将直接执行其后的无效指令。由于1字节是x86上指令能得到的最短字节,我们保证只有我们想要中断的指令才会被更改。
随心所欲"的断点
在x86中由于是使用int3中断触发的断点,如果在x86架构gdb中将断点设置在指令的非首字节(中间或末尾),根据gdb的工作原理,会将目标地址的第一个字节替换为int 3指令,然后触发断点后再换回去,将被跟踪进程的指令指针回滚一位。(这也就是指导书中说的“偷龙转凤”)因此,这时候回滚的位置可能并不符合预期。事实上gdb在这种情况下也会报错。
NEMU的前世今生
NEMU是通过监视点来模拟断点的,而gdbz正如上文所示是通过创建ptrace进程命中操作系统的int3中断完成的。
I386手册
尝试通过目录定位关注的问题
假设你现在需要了解一个叫 selector 的概念,请通过 i386 手册的目录确定你需要阅读手册中的哪些地方.
可以通过搜索解决问题。关于selector的详细阐述在内存管理部分,
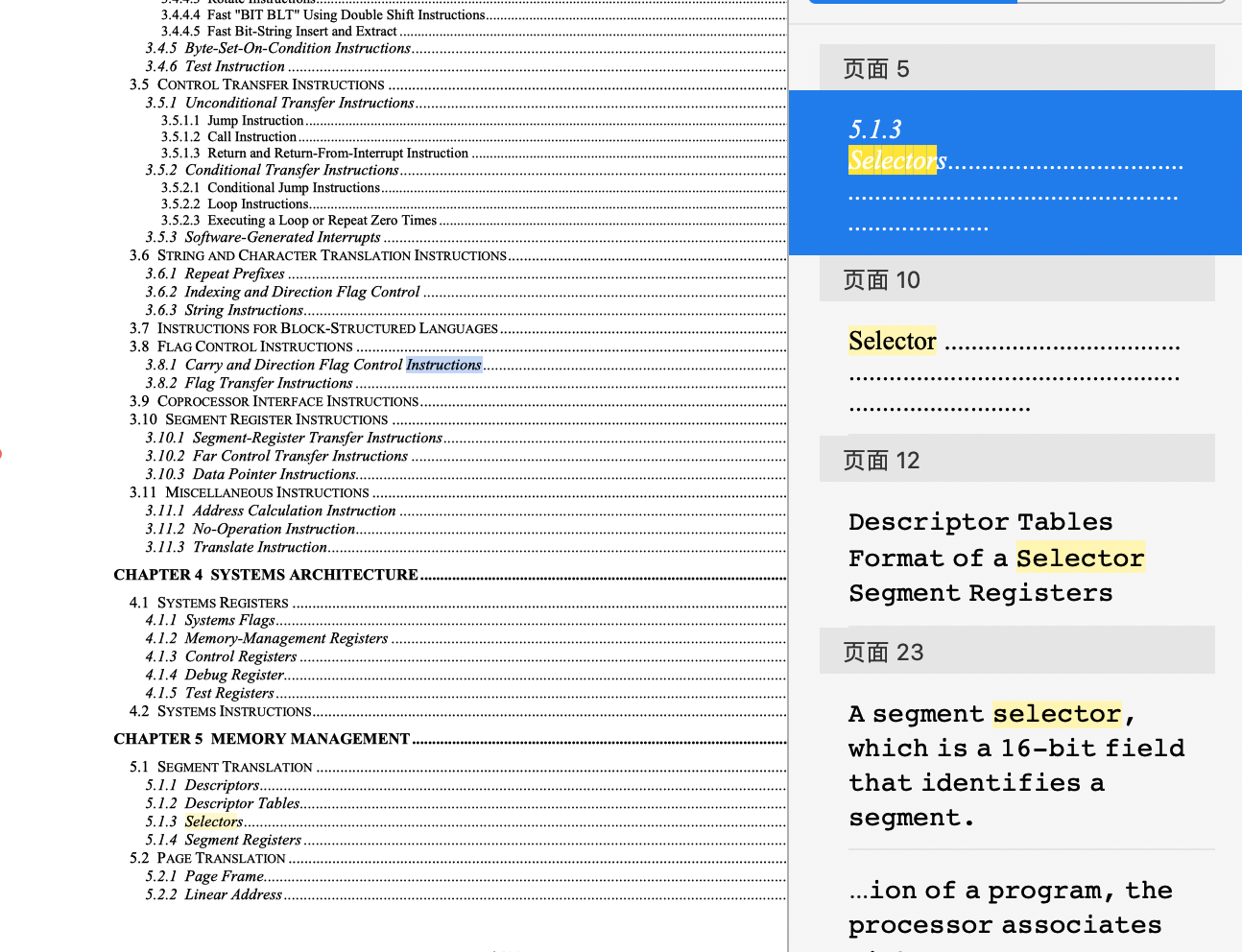
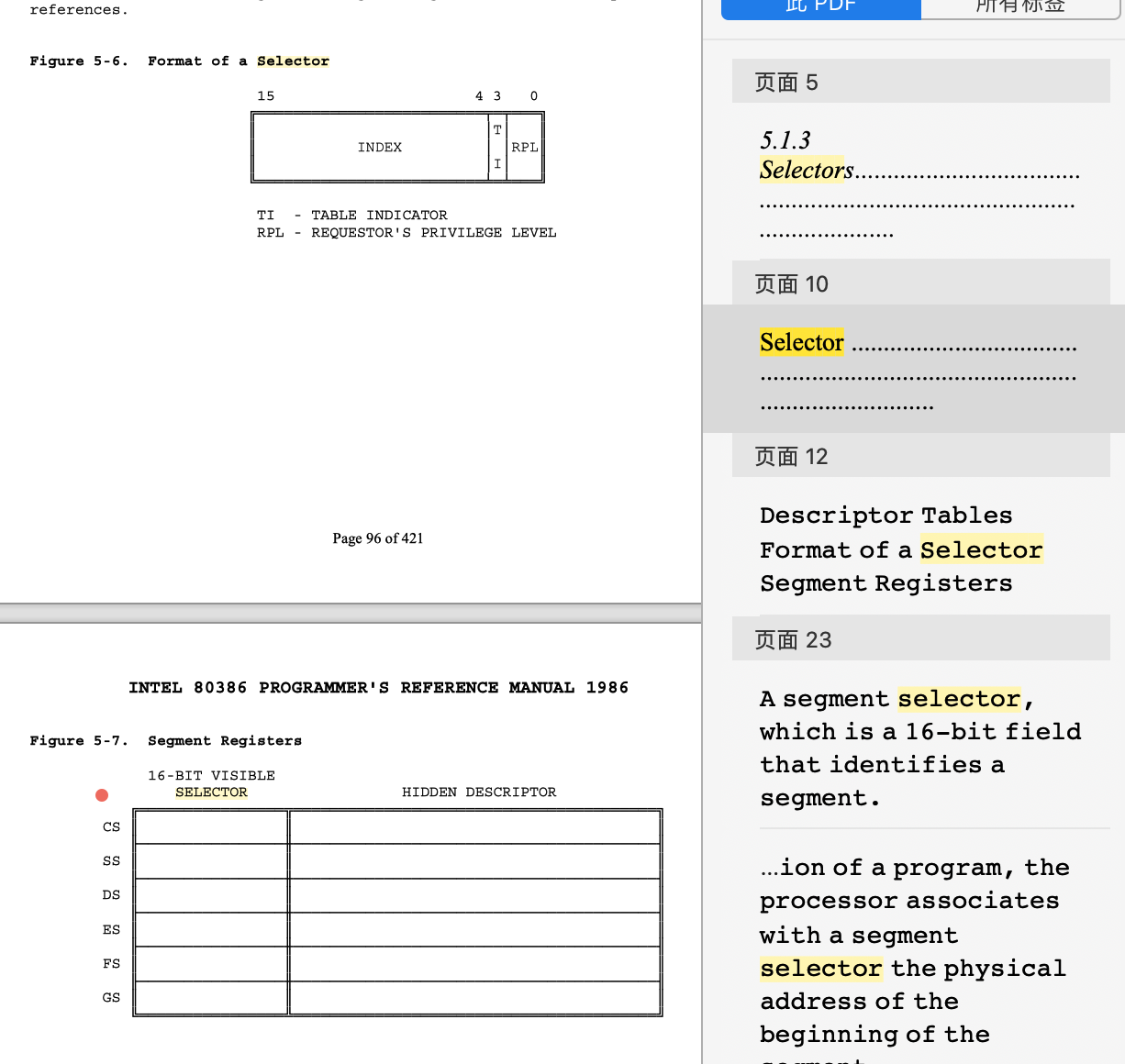
点进去就可以看到段选择子的格式。
必答题
一、
1、EFLAGS 寄存器中的 CF 位是什么意思?
CF是进位标志,在最高位发生进位或借位后将CF位置1,否则置0。
2、ModR/M 字节是什么?
ModR/M由Mod,Reg/Opcode,R/M三部分组成。Mod是前两位,用来寄存器寻址和内存寻 址;Reg/Opcode是中间三位,Reg代表使用的寄存器,Opcode则是对group的Opcode进行补 充;R/M为最后三位,与Mod结合起来可以得到8个寄存器和24个内存寻址。
3、mov 指令的具体格式是怎么样的? 格式是DEST ← SRC。
二、
find . -name "*[.h/.c]" | xargs wc -l利用正则表达式,可以如下方式获取非空行代码行数
find . -name "*[.h/.c]" | xargs grep "^." | wc -l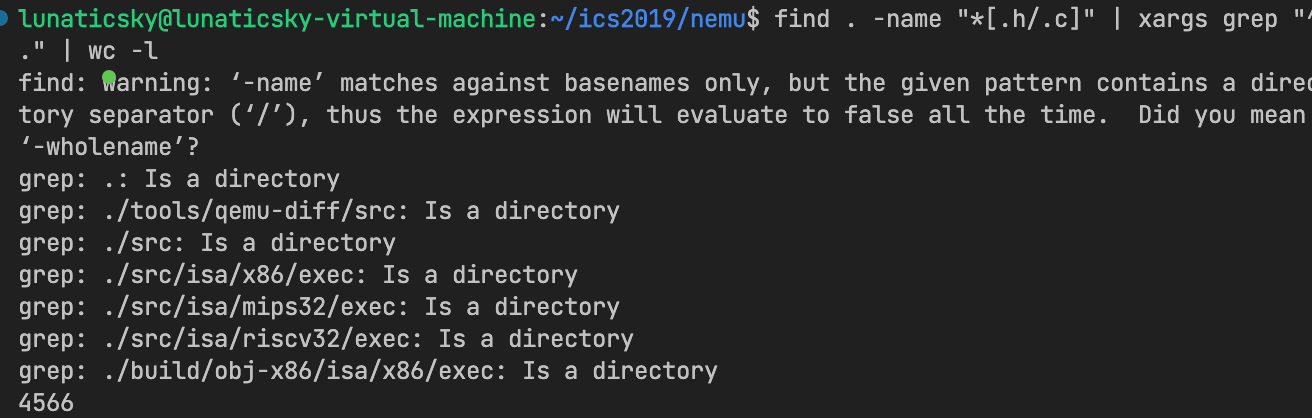
git checkout到原来的状态后结果如下:
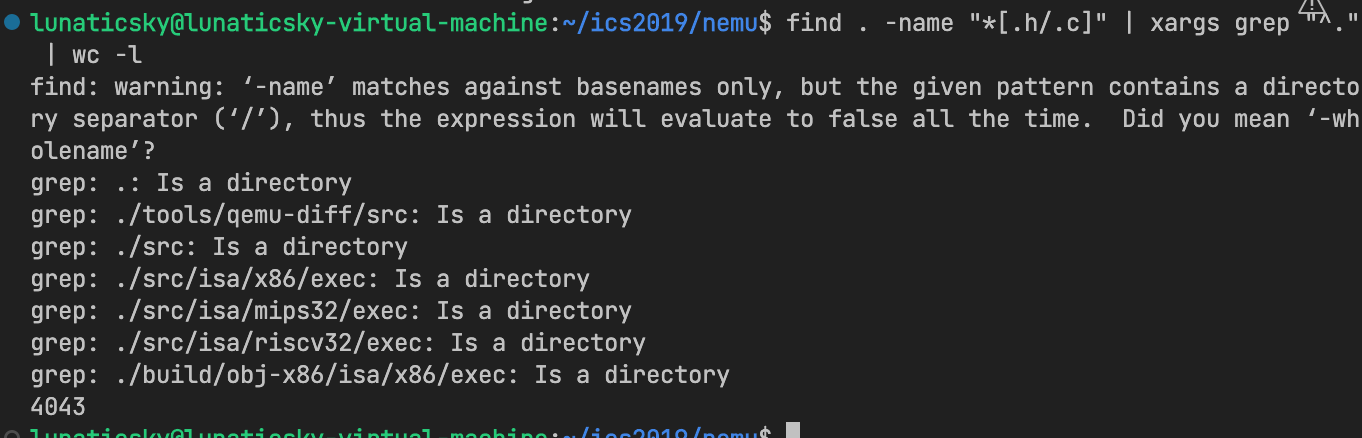
可以看到这次PA总共写了523行代码。
三、
-Wall 打开所有警告,使用GCC进行编译后产生尽可能多的警告信息,取消编译操作,打印 编译时所有错误或警告信息。
-Werror 要求GCC将所有的警告当成错误进行处理,取消编译操作。
使用-Wall和-Werror就是为了找出所有存在的警告,从而尽可能地避免程序运行出错。
这次实验的很多错误的发现都有这个的帮助。不过有时候gcc的检查也会显得过于严格。比如下面eval函数虽然已经包含了所有分支的处理,但最后还是要求我们return一个值。