南京大学ics2019_PA2
PA2实验报告
2013599 田佳业
关于PA究竟整了个什么的问题
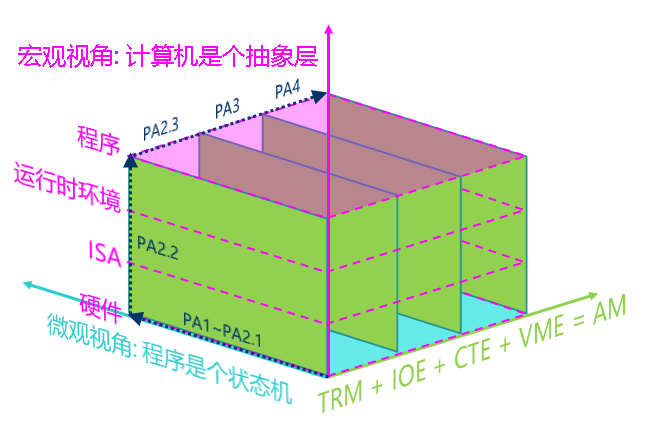
一阶段
任务
熟悉添加指令的流程,完成dummy程序运行。并且真正学会RTFM。
遇到的问题
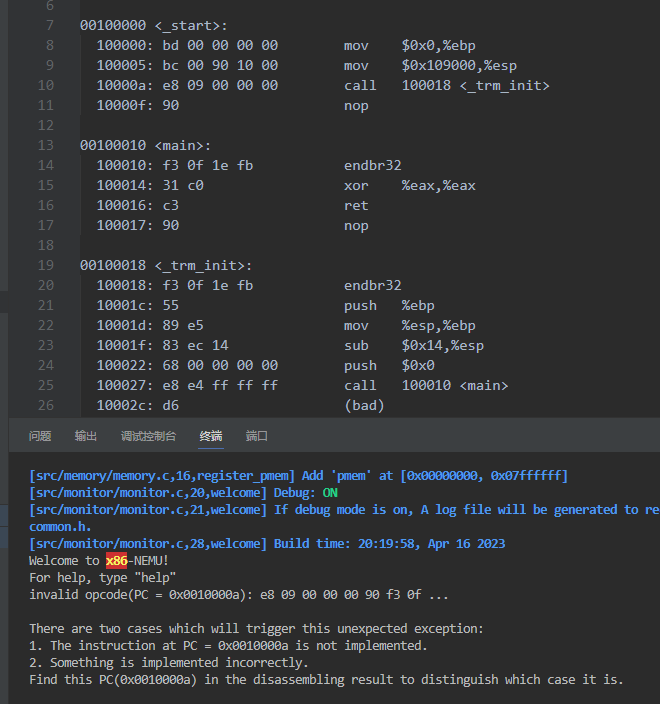
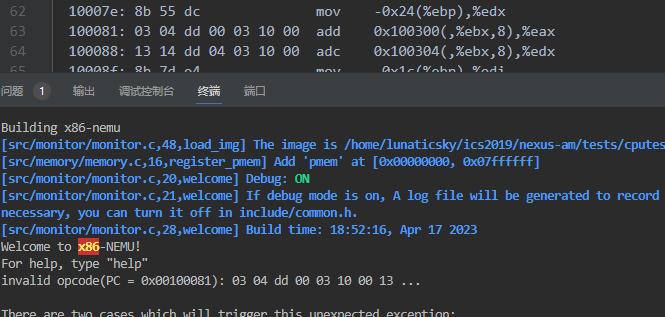
1.运行make ARCH=x86-nemu ALL=dummy run出现如图所示错误:
fatal error: bits/libc-header-start.h: No such file or directory
解决方法:
sudo apt-get install gcc-multilib因为我们是要模拟一个i386的isa,它是32位的。
之后又遇到下述错误:
/home/lunaticsky/ics2019/nexus-am/am/src/nemu-common/trm.c: In function ‘_trm_init’:
/home/lunaticsky/ics2019/nexus-am/am/src/nemu-common/trm.c:26:15: error: array subscript -1048576 is outside array bounds of ‘const char[1]’ [-Werror=array-bounds]
26 | const char *mainargs = &_start - 0x100000;
| ^~~~~~~~
/home/lunaticsky/ics2019/nexus-am/am/src/nemu-common/trm.c:25:21: note: while referencing ‘_start’
25 | extern const char _start;
| ^~~~~~这个错误并没有找到理想的解决方法。为了能够继续完成实验,只好把Makefile.compile的Werror编译选项去掉了。这不是一个优雅的解决方案。
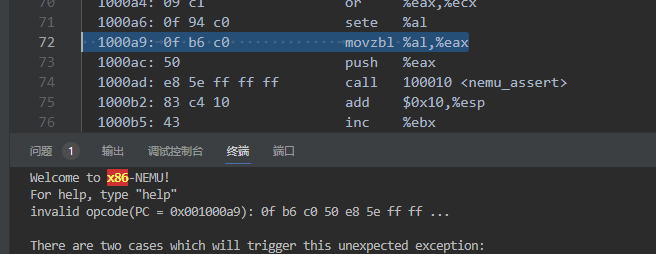
2.按照问题汇总trm_init 和 main 函数的开头出现 endbr32 指令部分
在 AM_HOME/makefile.compile 文件中,在和 nemu 有关的 CFLAGS 后面添加-fcf-protection=none 和-mmanual-endbr的方法修改后makefile报错
加了换行没加反斜杠。。
实现新指令
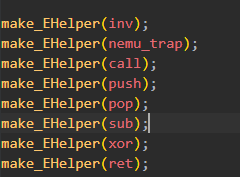
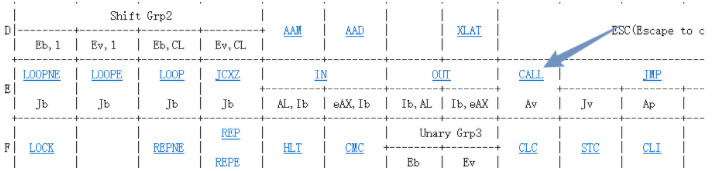
可以看到第一个我们需要实现的指令是call指令。
首先在nemu/src/isa/x86/exec/all-instr.h把需要实现的指令声明。
call_prepare
这里顺带把后面几个可能用到的也填了:
可以这些opcode都是单字节的,填opcode_table的时候千万不要错填到2字节部分!
/* 0xe8 */ IDEX(I,call), IDEX(J,jmp), EMPTY, IDEXW(J,jmp,1),显然call 指令的实现中需要使用压栈操作,因此先去实现push指令。
push_prepare
这个指令学长贴心的给出了勘误:

填opcode_table
nemu/src/isa/x86/exec/exec.c
/* 0x50 */ IDEX(r, push), IDEX(r, push), IDEX(r, push), IDEX(r, push),
/* 0x54 */ IDEX(r, push), IDEX(r, push), IDEX(r, push), IDEX(r, push),ics2019把ISA相关的RTL伪指令放到了nemu/src/isa/$ISA/include/isa/rtl.h中定义,一开始去nemu/include没找到,后来发现指导手册里有说明,还是没仔细看。
static inline void rtl_push(const rtlreg_t* src1) {
// esp <- esp - 4
// M[esp] <- src1
//TODO();
rtl_subi(&cpu.esp, &cpu.esp, 4);
rtl_sm(&cpu.esp, src1, 4);
}而且一个坑是它的api和2018的是不一样的:
错误代码:
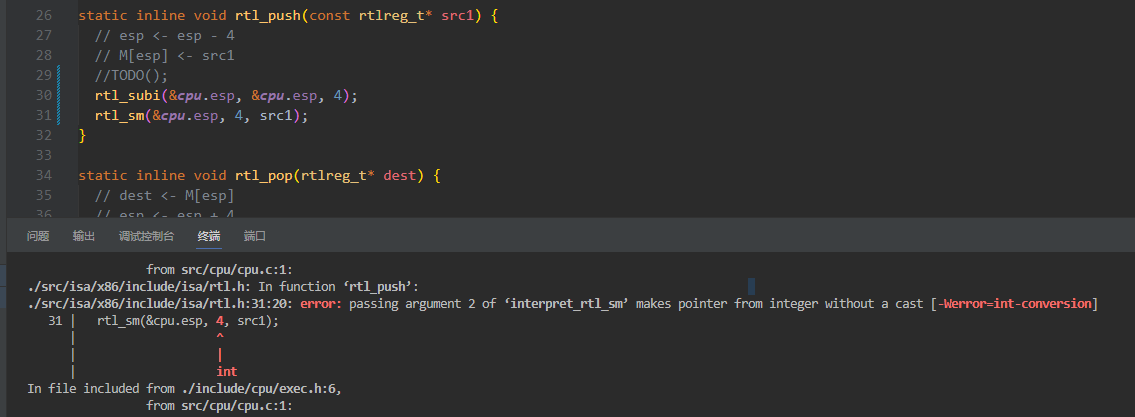
于是开始寻找这个函数的原型。
这是2018版

2019版在Vsocde找了半天没找到,看到唯一一个框架代码给出的示例,发现含义确实和预想的不一样,最后一个参数才是长度。
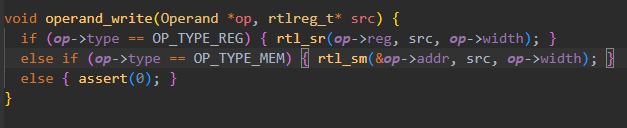
当然这个函数原型也是能找到的,只是因为rtl-wrapper.h做了包装,Vscode没法直接跳转而已。这个因为是体系结构抽象层的接口,在nemu/include/rtl/rtl.h里面。

sub
然后这时候发现,我们想实现push,sub都没实现哩。开始折磨起来了。
sub本身的实现不难。因为实验代码中给了更复杂的sbb指令的实现,仿照即可。代码如下:
make_EHelper(sub) {
//TODO();
rtl_sub(&s0,&id_dest->val,&id_src->val);
rtl_update_ZFSF(&s0,id_dest->width);
rtl_is_sub_carry(&s1,&s0,&id_dest->val);
rtl_set_CF(&s1);
rtl_is_sub_overflow(&s1,&s0,&id_dest->val,&id_src->val,id_dest->width);
//printf("%d %d\n",id_dest->val,id_src->val);assert(0);
rtl_set_OF(&s1);
operand_write(id_dest,&s0);
print_asm_template2(sub);
}还要注意一点,在文档的附录里面说了,x86使用ModR/M字节中的扩展opcode域来对opcode的长度进行扩充.
有些时候, 读入一个字节也还不能完全确定具体的指令形式,
这时候需要读入紧跟在opcode后面的ModR/M字节,
把其中的reg/opcode域当做opcode的一部分来解释,
才能决定具体的指令形式. x86把这些指令划分成不同的指令组(instruction
group)。
框架代码的make_group就是干这事的,不加跑不起来,因为译码的时候要用。
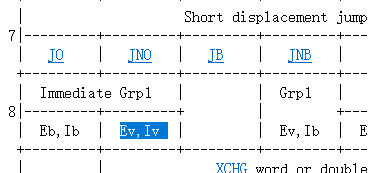
/* 0x80, 0x81, 0x83 */
make_group(gp1,
EX(add), EX(or), EX(adc), EX(sbb),
EX(and), EX(sub), EX(xor), EX(cmp))这几个位置涉及到变长指令,比如
100017: 83 ec 14 sub $0x14,%esp就是这一类的。
实现sub的主要问题是还需要实现eflags。
eflags
eflags各位的含义
CF(bit 0) [Carry flag] 若算术操作产生的结果在最高有效位(most-significant bit)发生进位或借位则 将其置 1,反之清零。这个标志指示无符号整型运算的溢出状态,这个标志同样 在多倍精度运算(multiple-precision arithmetic)中使用。
ZF(bit 6) [Zero flag] 若结果为 0 则将其置 1,反之清零。
SF(bit 7) [Sign flag] 该标志被设置为有符号整型的最高有效位。(0 指示结果为正,反之则为负)
IF(bit 9) [Interrupt enable flag] 该标志用于控制处理器对可屏蔽中断请求(maskable interrupt requests)的响 应。置 1 以响应可屏蔽中断,反之则禁止可屏蔽中断。
OF(bit 11) [Overflow flag] 如果整型结果是较大的正数或较小的负数,并且无法匹配目的操作数时将该 位置 1,反之清零。这个标志为带符号整型运算指示溢出状态。
我们可以用位域实现eflag结构,它本质上就是一个结构体。把它放到CPU_state结构体里面。
union{
struct{
uint32_t CF:1;
unsigned :5;
uint32_t ZF:1;
uint32_t SF:1;
unsigned :1;
uint32_t IF:1;
unsigned :1;
uint32_t OF:1;
signed :20;
};
uint32_t val;
}eflags;不要忘了eflags 的初始化。
static void restart() {
/* Set the initial program counter. */
cpu.pc = PC_START;
cpu.eflags.val = 0x2;
}这时候再运行,发现eflag更新相关的rtl方法还没实现。
下面是更新ZF标志的方法,根据不同长度判断相与是否为0.或许可以有更好的方法或者可以调用接口实现,不过如文档所说,先完成再完美。
switch (width)
{
case 4:
{
t0 = (*result == 0);
rtl_set_ZF(&t0);
break;
}
case 2:
{
t0 = ((*result & 0xffff) == 0);
rtl_set_ZF(&t0);
break;
}
case 1:
{
t0 = ((*result & 0xff) == 0);
rtl_set_ZF(&t0);
break;
}
default:
assert(0);
}框架还要求我们去实现一个设置标志位的宏。就连这么小的一个功能都要抽象成一个宏,而不是复制黏贴设置src和dest,相较文档中的哲学确实做到了言行一致。
#define make_rtl_setget_eflags(f) \
static inline void concat(rtl_set_, f) (const rtlreg_t* src) { \
cpu.eflags.f=*src; \
} \
static inline void concat(rtl_get_, f) (rtlreg_t* dest) { \
*dest=cpu.eflags.f; \
}中间还涉及要要求判断何时“溢出”和“借位”以及判断有效最高位。虽然计算机使用补码运算,没有“借位”这一概念,但减法变成补码加法运算的时候没进位,其实就是借位了。这一部分的实现是真·小学知识,但确实很琐碎,具体代码不在报告展示了。
push
nemu/src/isa/x86/exec/data-mov.c
make_EHelper(push) {
//TODO();
rtl_push(&id_dest -> val);
print_asm_template1(push);
}call
下面就可以把call的make_EHelper补充完整了。ics2019为了照顾不同的ISA,相比2018改了一些变量名。
make_EHelper(call) {
// the target address is calculated at the decode stage
// TODO();
rtl_push(pc); //push pc
rtl_j(decinfo.jmp_pc);
print_asm("call %x", decinfo.jmp_pc);
}call指令是先将当前的pc压入栈中,再转移 eip。转移eip这一步需要J指令。
J指令看上去已经实现好了,但是运行还是不正确。仔细想了一下指令的执行步骤,找了代码,发现连J的译码用到了make_DopHelper(SI)。连这个都得要求自己实现。
可以看到现在call指令已经能够运行了。
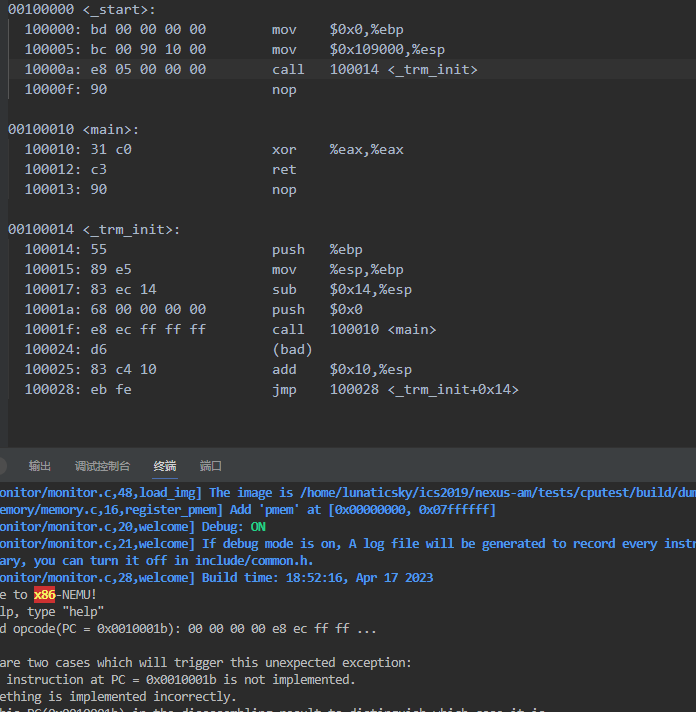
可以看到push的实现并不完善,它没有识别到后面的立即数。通过操作码定位到发现是make_DopHelper(SI)函数实现出现了问题,改正即可。
整体来看,实现call的过程像是栈工作的过程:随着问题的发现任务栈逐渐加深,步步为营解决了细节问题之后,带领我们来到细节问题的,初看上去很吓人的问题也随之解决了(pop)。不管是做高中压轴题,做PA,还是学习新知识,做项目,经历了上山的过程才有下山的愉悦。
回到PA。这一阶段还没完呢矮油喂。。
pop
pop的实现和push类似,虽然在一阶段用不到,反正迟早要做,就一起写了。
/* 0x58 */ IDEX(r, pop), IDEX(r, pop), IDEX(r, pop), IDEX(r, pop),
/* 0x5c */ EMPTY, IDEX(r, pop), IDEX(r, pop), IDEX(r, pop),static inline void rtl_pop(rtlreg_t* dest) {
// dest <- M[esp]
// esp <- esp + 4
// TODO();
rtl_lm(dest, &cpu.esp, 4);
rtl_addi(&cpu.esp, &cpu.esp, 4);
}make_EHelper(pop)
{
// TODO();
rtl_pop(&t0); // register t0 is used according to the convention
if (id_dest->type == OP_TYPE_REG) // dest is register, write to register
{
rtl_sr(id_dest->reg, id_dest->width, &t0);
}
else if (id_dest->type == OP_TYPE_MEM) // dest is memory, write to memory
{
rtl_sm(&id_dest->addr, id_dest->width, &t0);
}
else
{
//should not reach here
assert(0);
}
print_asm_template1(pop);
}xor
现在来到了xor。经历了实现call指令的折磨,对实现xor也更有信心了。
xor的执行函数在logic.c里面。
仿照着写,并不难。
make_EHelper(xor)
{
rtl_li(&s1,0);
rtl_set_OF(&s1);
rtl_set_CF(&s1);
rtl_xor(&s0,&id_dest->val,&id_src->val);
rtl_update_ZFSF(&s0,id_dest->width);
operand_write(id_dest,&s0);
print_asm_template2(xor);
}对照手册,我们需要关心的opcode是0x30-0x35。

ret
dummy跑通的临门一脚。
先去附录找到c3对应的内容,定位到ret的页面:

可以看到ret有好几种形式。但是我们显然只需要实现c3就可以满足需要。
根据描述,C3 ret是用栈的数据修改IP的内容,实现近转移。
我们在操作系统课上学过,ret弹出栈中保存的eip,跳到对应地址就可以返回调用它的位置。注意设置跳转标志。
make_EHelper(ret)
{
rtl_pop(&decinfo.jmp_pc);
rtl_j(decinfo.jmp_pc);
print_asm("ret");
}HIT GOOD TRAP!
问题
立即数背后的故事
放到大端机上运行的时候内存布局,NEMU读取方式是一样的,但CPU的解释方式不一样了,因此会出问题。
怎么解决,既然NEMU是一个模拟器,就看QEMU是怎么解决的。模拟器确实需要解决这个问题
mips32和riscv32的指令长度只有32位, 因此它们不能像x86那样, 把C代码中的32位常数直接编码到一条指令中. mips32和riscv32应该如何解决这个问题?
我们在机组课上学过MIPS指令。MIPS是通过lui和ori用两条指令分别加载高16位和低16位立即数。
riscv虽然不甚了解,但查阅资料可知也是通过类似的思虑进行的。
拦截客户程序访存越界的非法行为
你将来很可能会遇到客户程序访存越界的错误, NEMU的框架代码一旦检测到这一行为就会直接panic. 这一行为的检测已经极大地帮助你发现代码的问题了, 想象一下, 如果NEMU并未拦截这一error, 你可能会看到怎么样的failure?
事实上访问到无法控制的内存,得到错误的结果甚至core dump。
神秘的host内存访问 (建议二周目思考)
为什么需要有host内存访问的RTL指令呢?
阅读源码发现,用到host内存访问指令的是
static inline void rtl_lr(rtlreg_t* dest, int r, int width) {
switch (width) {
case 4: rtl_mv(dest, ®_l(r)); return;
case 1: rtl_host_lm(dest, ®_b(r), 1); return;
case 2: rtl_host_lm(dest, ®_w(r), 2); return;
default: assert(0);
}
}lr或sr的时候宽度小于4
而guest内存访问和host内存访问指令的区别在于一个是直接赋值,另一个是经过了vaddr转换。
static inline void interpret_rtl_lm(rtlreg_t *dest, const rtlreg_t* addr, int len) {
*dest = vaddr_read(*addr, len);
}static inline void interpret_rtl_host_lm(rtlreg_t* dest, const void *addr, int len) {
switch (len) {
case 4: *dest = *(uint32_t *)addr; return;
case 1: *dest = *( uint8_t *)addr; return;
case 2: *dest = *(uint16_t *)addr; return;
default: assert(0);
}
}vaddr_read是由MMU来完成的。目前不是很明白调用不同宽度的lr会导致读的内存类型不一样,对这个问题也不太能做出满意的回答。
二阶段
关于AM做了什么的事情,学校手册特意标了红色:
AM 在概念上定义了一台抽象计算机,它从运行程序的视角刻画了一台计算机 应该具备的功能,而真机和 NEMU都是这台抽象计算机的具体实现,只是真机是通过物理上存在的数字电路来实现,NEMU 是通过程序来实现。
更多指令实现
任务
nemu目录运行
bash runall.sh ISA=x86可以看到第一个需要实现的是add_longlong。
这里面第一个需要实现的指令是lea

查表加上opcode_table之后提示我exec_and没实现。其实这不是lea的锅。因为框架把make_EHelper(lea)已经实现了,lea就这样完成了。实际上是因为10060的and指令导致的。
下一个是pushl。
在手册附录的Opcode Map发现这个位置是一个指令组:
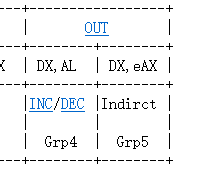
在Push页面能够看到对应的说明:

上网查阅,反汇编码 pushl 相当于
push dword。
这个pushl也是把指令组写了,把操作码写了,就完成了。

nop也得专门整个opcode
下面是add
看手册,正好一起把同类型的add都填了。
下面是adc。adc是带进位加法。其实开头的几个算术和逻辑指令格式都很像,参照着手册填下来就好了。
已经感受到这一部分更多的是体力活了。

可以看到0f是2byte-escape,这是我们遇到的第一个两字节操作码指令。查2字节的opcode,是这个

这一堆setx指令都很像,属于条件置位指令。

emm有一个手册里没有必须要看源码才知道的事情,就是nemu将这一类指令抽象成了setcc
执行阶段给出了实现:
make_EHelper(setcc) {
uint32_t cc = decinfo.opcode & 0xf;
rtl_setcc(&s0, cc);
operand_write(id_dest, &s0);
print_asm("set%s %s", get_cc_name(cc), id_dest->str);rtl_setcc需要我们自己实现:
void rtl_setcc(rtlreg_t* dest, uint8_t subcode) {
bool invert = subcode & 0x1;
enum {
CC_O, CC_NO, CC_B, CC_NB,
CC_E, CC_NE, CC_BE, CC_NBE,
CC_S, CC_NS, CC_P, CC_NP,
CC_L, CC_NL, CC_LE, CC_NLE
};
// TODO: Query EFLAGS to determine whether the condition code is satisfied.
// dest <- ( cc is satisfied ? 1 : 0)
switch (subcode & 0xe) {
case CC_O:{rtl_get_OF(dest);break;}
case CC_B:{rtl_get_CF(dest);break;}
case CC_E:{rtl_get_ZF(dest);break;}
case CC_BE:{rtl_get_CF(&t0);rtl_get_ZF(&t1);rtl_or(dest,&t0,&t1);break;}
case CC_S:{rtl_get_SF(dest);break;}
case CC_L:{rtl_get_SF(&t0);rtl_get_OF(&t1);rtl_xor(dest,&t0,&t1);break;}
case CC_LE:{rtl_get_SF(&t0);rtl_get_OF(&t1);rtl_xor(dest,&t0,&t1);rtl_get_ZF(&t0);rtl_or(dest,dest,&t0);break;}
//TODO();
default: panic("should not reach here");
case CC_P: panic("n86 does not have PF");
}
if (invert) {
rtl_xori(dest, dest, 0x1);
}
assert(*dest == 0 || *dest == 1);
}这一部分主要根据指令含义和文档完成。
至于填opcode_table,理解了之后自然就知道要填到下面一组了。
0f是2字节opcode,找第二个mapb对应的那一行
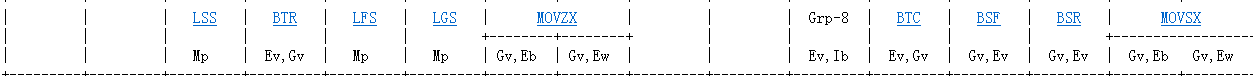
可以看到movvsx和movvzx。这两个指令都是在mov的基础上加了符号拓展功能。
可以看到框架里已经实现了,填表即可。
/* 0xb4 */ EMPTY, EMPTY, IDEXW(mov_E2G,movzx,1), IDEXW(mov_E2G,movzx,2),
/* 0xb8 */ EMPTY, EMPTY, EMPTY, EMPTY,
/* 0xbc */ EMPTY, EMPTY, IDEXW(mov_E2G,movsx,1), IDEXW(mov_E2G,movsx,2),
test
根据手册,TEST 计算其两个操作数的按位逻辑与。 每一位如果操作数的对应位均为 1,则结果为 1,否则为0.运算结果被丢弃,只改变标志寄存器。

据此实现即可。
make_EHelper(test) {
rtl_li(&s1,0);
rtl_set_OF(&s1);
rtl_set_CF(&s1);
rtl_and(&s0,&id_dest->val,&id_src->val);
rtl_update_ZFSF(&s0,id_dest->width);
print_asm_template2(test);
}
框架将这一类型的执行抽象成了jcc,调用了之前提到的setcc。因此可以这样填:
/* 0x70 */ IDEXW(J,jcc,1),IDEXW(J,jcc,1),IDEXW(J,jcc,1),IDEXW(J,jcc,1),
/* 0x74 */ IDEXW(J,jcc,1),IDEXW(J,jcc,1),IDEXW(J,jcc,1),IDEXW(J,jcc,1),
/* 0x78 */ IDEXW(J,jcc,1),IDEXW(J,jcc,1),IDEXW(J,jcc,1),IDEXW(J,jcc,1),
/* 0x7c */ IDEXW(J,jcc,1),IDEXW(J,jcc,1),IDEXW(J,jcc,1),IDEXW(J,jcc,1),
leave

填表,补充执行逻辑:
make_EHelper(leave) {
// TODO();
rtl_mv(&cpu.esp,&cpu.ebp);
rtl_pop(&cpu.ebp);
print_asm("leave");
}
dec,inc,cmp
make_EHelper(cmp) {
// TODO();
rtl_sub(&s0,&id_dest->val,&id_src->val);
rtl_update_ZFSF(&s0,id_dest->width);
rtl_is_sub_carry(&s1,&s0,&id_dest->val);
//printf("%d %d %d %d\n",s1,s0,id_dest->val,id_dest->width);
rtl_set_CF(&s1);
rtl_is_sub_overflow(&s1,&s0,&id_dest->val,&id_src->val,id_dest->width);
rtl_set_OF(&s1);
//if (id_src->val==0x40) printf("bian=%d\n",id_dest->val);
print_asm_template2(cmp);
}
make_EHelper(inc) {
// TODO();
rtl_li(&s1,1);
rtl_add(&s0,&id_dest->val,&s1);
rtl_update_ZFSF(&s0,id_dest->width);
rtl_is_add_overflow(&s1,&s0,&id_dest->val,&s1,id_dest->width);
rtl_set_OF(&s1);
operand_write(id_dest,&s0);
print_asm_template1(inc);
}dec一样的道理,就不放了。
终于迎来了二阶段的第一个HIT GOOD
TRAP!
加上中间填op_table习惯性的把旁边的也填了,其实现在就已经过的不少了。而且也发现名称排列和难度并不是对应的。。。
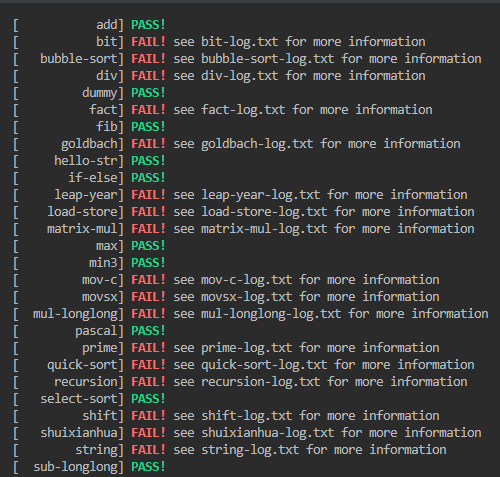
比如add里面有一个0x6a打头的push,中间做的时候也把它写了。
bit里面这个指令还过不去

看手册是Shift Grp2的指令,看源码是sar指令。

这一组带S指令都有移位功能,源码里的TODO也挨着,就对着手册一起做了。
框架中没有exec_rol,现在make_group的时候加上会报错。
这个是not,对应第三个指令组,开填。
至于实现,这应该是最简单的一个。。。
make_EHelper(not) {
// TODO();
rtl_not(&s0,&id_dest->val);
operand_write(id_dest,&s0);
print_asm_template1(not);
}还有一个rtl_not
static inline void rtl_not(rtlreg_t *dest, const rtlreg_t* src1) {
// dest <- ~src1
// TODO();
*dest=~(*src1);
}
到div了。
imul

填表即可。

符号拓展
这个要填rtl。利用好抽象层的东西。不就是把低位搬到高位么。
static inline void rtl_sext(rtlreg_t* dest, const rtlreg_t* src1, int width) {
// dest <- signext(src1[(width * 8 - 1) .. 0])
// TODO();
rtl_shli(&t0,src1,32-width*8);
rtl_sari(dest,&t0,32-width*8);
}下面指令果然涉及到了符号拓展。
手册里说这个位置是cwd,但
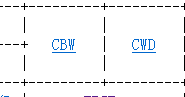
框架中给的是cltd和cwtl,cltd就是CWD/CDQ,而cwtl对应CBW/CWDE。
按理说可以调抽象层的接口,但我总是调不对。。只好重新造轮子了。
make_EHelper(cltd) {
if (decinfo.isa.is_operand_size_16) {
//TODO();
if ((cpu.eax>>15)&1) cpu.edx|=0x0000ffff;
else cpu.edx&=0xffff0000;
}
else {
//TODO();
if ((cpu.eax>>31)&1) cpu.edx|=0xffffffff;
else cpu.edx&=0;
}
print_asm(decinfo.isa.is_operand_size_16 ? "cwtl" : "cltd");
}
make_EHelper(cwtl) {
if (decinfo.isa.is_operand_size_16) {
//TODO();
if ((cpu.eax>>7)&1) cpu.eax|=0x0000ff00;
else cpu.eax&=0xffff00ff;
}
else {
if ((cpu.eax>>15)&1) cpu.eax|=0xffff0000;
else cpu.eax&=0x0000ffff;
}
print_asm(decinfo.isa.is_operand_size_16 ? "cbtw" : "cwtl");
}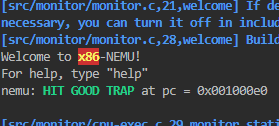
还差两个
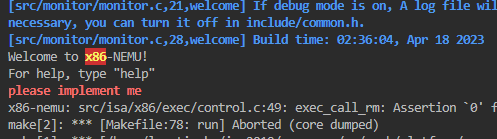
recursion,call_rm没实现。
手册上call写的很长,只需要关注r/m部分就可以了

对应实现:
make_EHelper(call_rm) {
//TODO();
rtl_li(&s0,id_dest->val);
rtl_mv(&decinfo.jmp_pc,&s0);
//decinfo.is_jmp=1;
rtl_push(pc);
rtl_j(decinfo.jmp_pc);
print_asm("call *%s", id_dest->str);
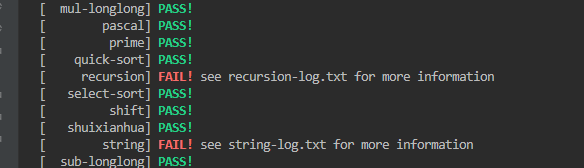
}这时候发现只有string过不了了。
一开始看到运行到了bad指令以为是自己跳转指令实现的有问题,回去检查了一遍没发现毛病,看指导书才发现是自己少做了东西。然后2020版的文档这个位置就挨着不要以为有TDDO才需要实现的免责声明。多少有点挑衅了。但又不能说什么,谁让我没好好看文档。。。
按照指导书提示,要完成string.c中列出的字符串处理函数才能通过这个样例。看源代码实现下面三个函数就可以了。我们只需要通过直接操作字符来完成库函数本应有的功能即可。
char* strncpy(char* dst, const char* src, size_t n) {
char* pd=dst;
while (n>0&&*src!='\0') --n,*pd=*src,++pd,++src;
while (n>0) --n,*pd='\0',++pd;
return dst;
}
char* strcat(char* dst, const char* src) {
char* pd=dst;
while (*pd!='\0') ++pd;
while (*src!='\0') *pd=*src,++pd,++src;
*pd='\0';
return dst;
}
int strcmp(const char* s1, const char* s2) {
while (*s1!='\0'&&*s2!='\0'&&*s1==*s2) ++s1,++s2;
if (*s1>*s2) return 1;
else if (*s1<*s2) return -1;
else return 0;
}另外sprintf也是一样的单例。网上有很多参考,如这个。就不展开了。
然后发现neg没实现。实现了就好。
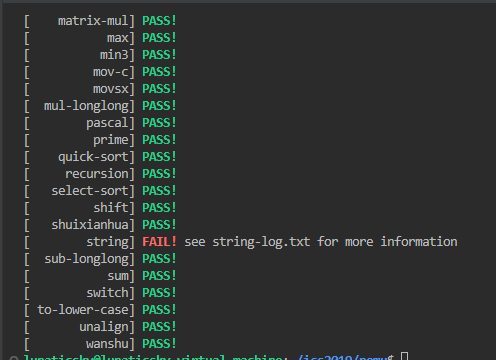
顺利AP。
问题
为什么要有AM?
AM的主要目的是程序和架构解耦,也就是屏蔽底层指令集架构的差异,让程序不必关心底层的架构。而操作系存在的目的主要是控制多道程序运行调度,,并提供文件访问,网络,输入输出等方便调用的接口。从功能上AM和OS有所重叠,但在抽象层次上AM是处于操作系统下层的。
堆和栈在哪里?
这个问题2019没有,看了学校手册才知道。
堆和栈在内存里。
为什么堆和栈的内容没有放入可执行文件里面?那程序运行时刻用到的堆和栈又是怎么来的?
因为堆和栈的大小是在运行时确定的,它们的内容无法在编译时被包含在可执行文件中。相反,它们的大小和位置由操作系统根据程序的需要在运行时进行动态分配和管理。
指令名对照
对于x86手册附录有opcode-map,直接根据指令的opcode查询即可,不必非得通过名称查询。这建立在指令名本身只是方便记忆的助记符,二手册对opcode的指令功能和解码方式进行的约定。
difftest
任务
difftest的实现我们只需要实现检查寄存器的环节即可。
nemu/src/isa/mips32/diff-test.c
bool isa_difftest_checkregs(CPU_state *ref_r, vaddr_t pc) {
if ((*ref_r).eax!=cpu.eax||(*ref_r).ecx!=cpu.ecx
||(*ref_r).edx!=cpu.edx||(*ref_r).ebx!=cpu.ebx
||(*ref_r).esp!=cpu.esp||(*ref_r).ebp!=cpu.ebp
||(*ref_r).esi!=cpu.esi||(*ref_r).edi!=cpu.edi
||(*ref_r).pc!=cpu.pc) return 0;
return 1;
}xxxxxxxxxx bool isa_difftest_checkregs(CPU_state *ref_r, vaddr_t pc) { if ((*ref_r).eax!=cpu.eax||(*ref_r).ecx!=cpu.ecx ||(*ref_r).edx!=cpu.edx||(*ref_r).ebx!=cpu.ebx ||(*ref_r).esp!=cpu.esp||(*ref_r).ebp!=cpu.ebp ||(*ref_r).esi!=cpu.esi||(*ref_r).edi!=cpu.edi ||(*ref_r).pc!=cpu.pc) return 0; return 1;}nemu/src/isa/mips32/diff-test.c问题
API约定
实验指导书中提到,在介绍API约定的时候,
提到了寄存器状态r需要把寄存器按照某种顺序排列.
qemu-diff作为REF, 已经满足API的这一约束. 让我们RTFSC,
从中找出这一顺序, 并检查你的NEMU实现是否已经满足约束.
我们从宏定义入手,看开启difftest时nemu执行了哪些步骤,指导书其实也有阐述。
调用init_difftest(),初始化,其中包括从动态库中读取API的符号
nemu/src/monitor/diff-test/diff-test.c-void init_difftest

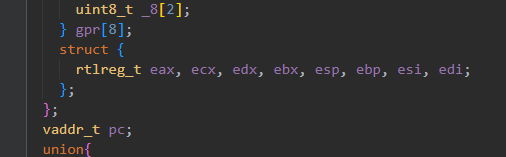
给ref_difftest_setregs传入的参数是cpu。在PA1中我们完成了这个结构体,寄存器顺序如下:
再看调用的API:
nemu/tools/qemu-diff/src/diff-test.c
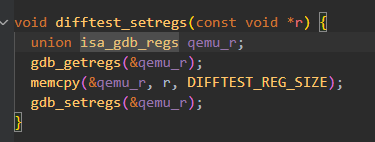
nemu/tools/qemu-diff/src/isa/x86/include/isa.h
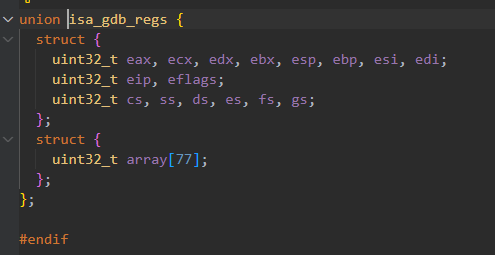
可以看到顺序是符合约定的。其中array是存gdb通信的字符串消息的。
匪夷所思的QEMU行为
这个确实不了解,不过根据指导书,x86也没有这种行为。
捕捉死循环
如果我们是像Difftest一样在实现的过程检验实现是否正确(在这次实验中死循环和bad instruction引起的问题确实不好定位,difftest也无能为力,定位到的指令离实际出现的指令十万八千里。只能根据git记录依次检查自己实现的指令可能存在的问题。),可以采用在naive上记录动态指令执行的指令数,然后执行的时候如果超过了这个指令数就终止。而作为模拟器去检查死循环,可以采用静态代码分析的方式进行。执行起来的时候检查比较难,因为比如设置阈值,其实不知道是程序死循环了还是真的想执行这么多次。
三阶段
任务
别忘了把HAS_IOE打开。
串口
选x86有福了。还要实现in,
out指令。还好这个也不难,在它们的执行辅助函数中分别调用
pio_read_[l|w|b]()和pio_write_[l|w|b]()函数即可。
make_EHelper(in) {
// TODO();
if (id_dest->width==4) s0=pio_read_l(id_src->val);
else if (id_dest->width==2) s0=pio_read_w(id_src->val);
else s0=pio_read_b(id_src->val);
operand_write(id_dest,&s0);
print_asm_template2(in);
}
make_EHelper(out) {
// TODO();
if (id_dest->width==4) pio_write_l(id_dest->val,id_src->val);
else if (id_dest->width==2) pio_write_w(id_dest->val,id_src->val);
else if (id_dest->width==1) pio_write_b(id_dest->val,id_src->val);
else assert(0);
print_asm_template2(out);
}
看手册,果然是IN,OUT指令。在opcode_table里面补上即可。

时钟
这个部分看了半天没看明白要干什么,查阅网上资料才知道怎么做:
初始化时通过inl(RTC_ADDR)获取初始时间boot_time,随后uptime时同样读取时间,相减作为uptime->lo。
在_DEVREG_TIMER_UPTIMEcase里面:
unsigned long tt=(inl(RTC_ADDR)-init_tim);
// printf("%d\n",tt);
uptime->hi = 0;
uptime->lo = tt;后面没实现的初始化函数:
void __am_timer_init() {
init_tim=inl(RTC_ADDR);
}当然要增加一个静态全局变量init_tim把初始时间记下来。
至于怎么跑,make ARCH=native mainargs=H run可以看到:
因此可以make ARCH=x86-nemu mainargs=t run,当然naive也是可以对照着看的。
一开始发现进入之后不打印,一直死循环,发现是没有实现printf。补上就可以了。
跑分,随便跑了一个,现在性能还是比较拉胯。
键盘
和时钟相似。
case _DEVREG_INPUT_KBD:
{
_DEV_INPUT_KBD_t *kbd = (_DEV_INPUT_KBD_t *)buf;
uint32_t code_key = inl(KBD_ADDR);
if (code_key == _KEY_NONE)
{
kbd->keydown = 0;
kbd->keycode = _KEY_NONE;
}
else
{
if (code_key & 0x8000)
kbd->keydown = 1;
else
kbd->keydown = 0;
kbd->keycode = (code_key);
}
return sizeof(_DEV_INPUT_KBD_t);
}
VGA
static void vga_io_handler(uint32_t offset, int len, bool is_write) {
// TODO: call `update_screen()` when writing to the sync register
//TODO();
if (is_write)
{
update_screen();
}
}size_t __am_video_write(uintptr_t reg, void *buf, size_t size)
{
switch (reg)
{
case _DEVREG_VIDEO_FBCTL:
{
_DEV_VIDEO_FBCTL_t *ctl = (_DEV_VIDEO_FBCTL_t *)buf;
uint32_t p = 0;
uint32_t *ff;
for (int j = ctl->y; j < ctl->y + ctl->h; ++j)
for (int i = ctl->x; i < ctl->x + ctl->w; ++i)
{
ff = (uint32_t *)(uintptr_t)(FB_ADDR) + (j * 400);
ff[i] = ctl->pixels[p];
++p;
}
if (ctl->sync)
{
outl(SYNC_ADDR, 0);
}
return size;
}
}
return 0;
}
void __am_vga_init()
{
int i;
int size = screen_width() * screen_height();
uint32_t *fb = (uint32_t *)(uintptr_t)FB_ADDR;
for (i = 0; i < size; i++)
fb[i] = i;
draw_sync();
}
问题
volitle关键字
volitle关键字的基本含义是编译后的程序每次需要存储或读取这个变量的时候,告诉编译器对该变量不做优化,都会直接从变量内存地址中读取数据,从而可以提供对特殊地址的稳定访问。
参见这里
文中的例子便是手册中提及到的情形:
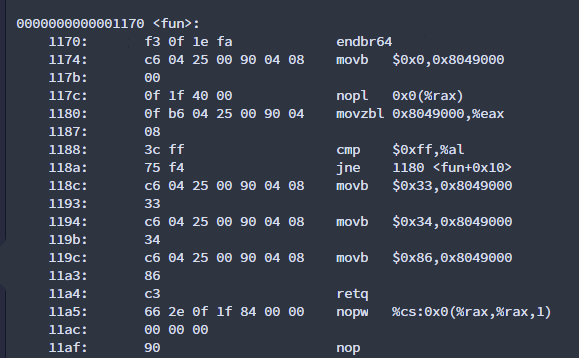
假设要对一个设备进行初始化,此设备的某一个寄存器为0x8049000
void fun(){
volatile unsigned char *p=(void *)0x8049000;
*p=0;
while(*p !=0xff);
*p=0x33;
*p=0x34;
*p=0x86;
}正常先循环读后写,一切正常。
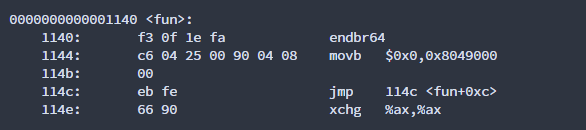
去掉volatile:
经过编译器优化后,编译器认为指针指向的内容都是0了,下面while肯定是一个死循环,就自己jmp自己了。表现在设备上,就是一直在读,写不进去,就出问题了。
如何检测多个键同时被按下?
键码相或即可。
必答题
整理一条指令的运行过程
这个问题2018版没有,事实上PA2第一部分指令系统的课件说的也非常详细。
编译与链接
inline 关键字实际上表示建议内联,gcc中O0优化时是不内联的。所以在头文件中用inline时务必加入static。 为了确保内联,头文件中用 inline 时务必加入 static,否则当 inline 不内联时就和普通函数在头文件中定义一样,当多个 c 文件包含时就会重定义。加入 static 后代码健壮性高,如果只是用 inline 时编译器都内联了,那两者的实际效果是一样的。
在我的环境下,去掉static和去掉inline是没有影响的。
但是都去掉,就报错了:
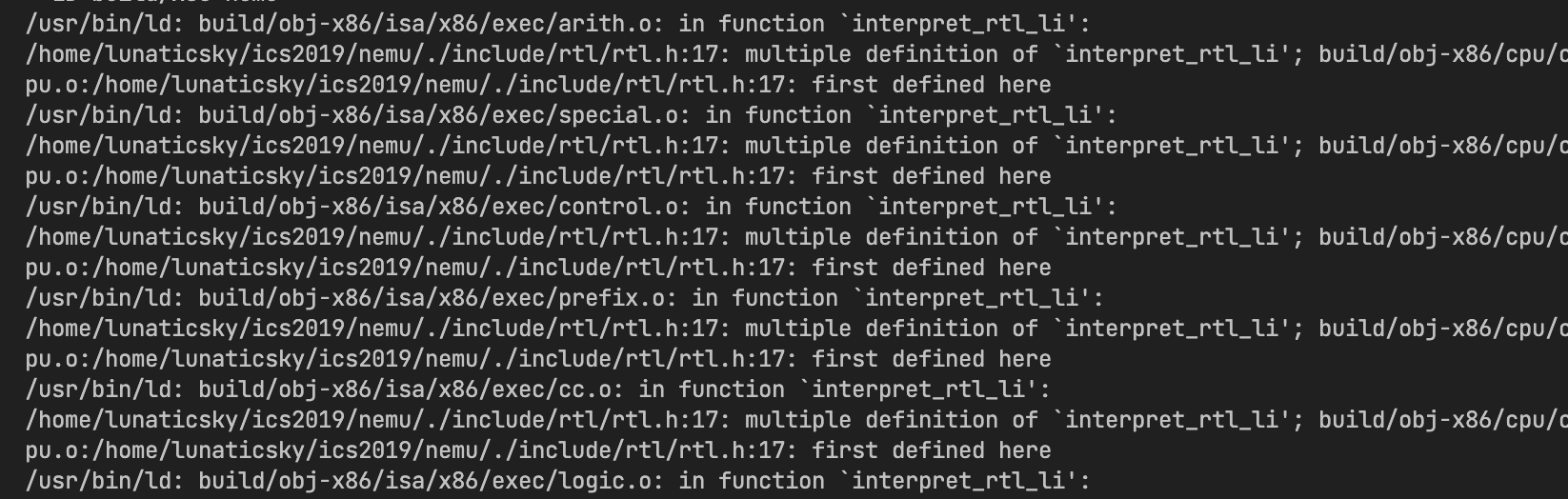
因为头文件会被许多文件引用所以如果去掉static inline,这个函数就会被多次定义,在链接的时候会报错。
重新编译NEMU.
请问重新编译后的NEMU含有38个dummy变量的实体(统计得到的加上common.h里的)

nemu/include/debug.h加了之后没变化(虽然理论上会多)
加上等于0,报错。
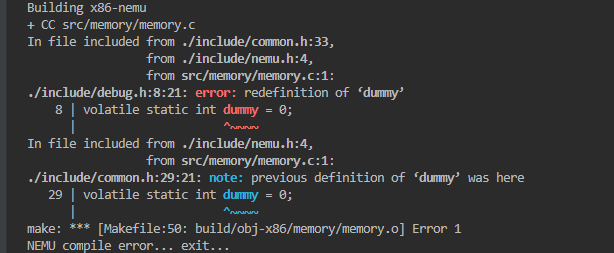
课上讲过,在C语言中只声明不初始化是一种弱定义,当声明多个同名同类型的变量时,编译不会报错,但是到了链接阶段,由于全是弱符号,链接器会随便选择一个。但是,有了初始化之后之后就不一样了,这变成了强定义,编译器无法忽略。
makefile执行过程
之前操作系统折磨过的一次makefile又回来折磨人了。 即便当时写了makefile急速入门,makefile这个东西不得不说和shell脚本一样,语法独具其风格,简练强大但可读性也不敢恭维。
我们输入make默认生成NEMU的二进制文件。
app: $(BINARY)再去看$(BINARY)的依赖:
$(BINARY): $(OBJS)
$(call git_commit, "compile")
@echo + LD $@
@$(LD) -O2 -rdynamic $(SO_LDLAGS) -o $@ $^ -lSDL2 -lreadline -ldlBINARY 依赖于 OBJS
OBJS = $(SRCS:src/%.c=$(OBJ_DIR)/%.o)(var:a=b),是将 var 变量中每一个单词后面的 a 替换为 b。所以OBJS其实就是build 文件夹下的所有.o 文件
OBJ_DIR是前面定义了的构建路径目标
OBJ_DIR ?= $(BUILD_DIR)/obj-$(ISA)$(SO)
BINARY ?= $(BUILD_DIR)/$(ISA)-$(NAME)$(SO)
关于SRC:
SRCS = $(shell find src/ -name "*.c" | grep -v "isa")
SRCS += $(shell find src/isa/$(ISA) -name "*.c")-v 表示不匹配“isa",先把isa文件夹排除掉,再根据选择的指令集去isa文件夹里面找。SRC包括构建NEMU用到的所有.c文件。
build 的各.o 文件依赖于 src 文件夹下的所有.c 文件。
$(OBJ_DIR)/%.o: src/%.c
@echo + CC $<
@mkdir -p $(dir $@)
@$(CC) $(CFLAGS) $(SO_CFLAGS) -c -o $@ $<
各.c 文件依赖于其中定义的.h 文件(隐含规则)
依赖关系终于分析完了。下面看到底执行了哪些操作。
$(BINARY)生成第一步,通知tracer去git
commit一下,commit信息是“compile”。这个函数是在Makefile.git里的,前面通过include引入。
第二步只是打印一下我现在要链接生成目标了。

最后一行便是生成NEMU的临门一脚。
顺便说一下执行make run 的过程。
NEMU_EXEC := $(BINARY) $(ARGS) $(IMG)定义参数:
override ARGS ?= -l $(BUILD_DIR)/nemu-log.txt
override ARGS += -d $(QEMU_SO)override的意思是不允许通过命令行指定的方式替代在Makefile中的变量定义。
执行出来就是这一句。

课后题
1.指令使用条件问题

为什么用jbe而不是jle?
jbe用于比较无符号数,jle用于比较有符号数。在 x86 中,内存地址被视为无符号整数,所以要用jbe。
至于为什么源代码里是大于,却用了小于等于,从各种角度看好像两种用法是等价的,不是很清楚CPU为什么要做这种转换。
下面是用jbe
get_cont:
movl 8(%ebp), %eax
movl 12(%ebp), %edx
cmpl %eax, %edx
ja .L1
movl (%eax), %eax
jmp .L2
.L1:
movl (%edx), %eax
.L2:2.nemu输出的helloworld和程序中输出的helloworld有什么区别
指导书在输入输出部分给出了这个问题的答案:
nemu的helloworld程序是可以说是直接运行在裸机上,可以在AM的抽象下直接输出到设备(串口);而我们在程序设计课上写的helloworld程序位于操作系统之上,不能直接操作设备,只能通过操作系统提供的服务进行输出,输出的数据要经过很多层抽象才能到达设备层。这个问题问的和为什么要有AM?这个问题很类似。