信息检索_索引构建、压缩及查询支持
信息检索第一部分--索引构建
倒排索引构建
六个步骤
序列化,语言预处理,分配DocID,排序,归并,添加频率标签
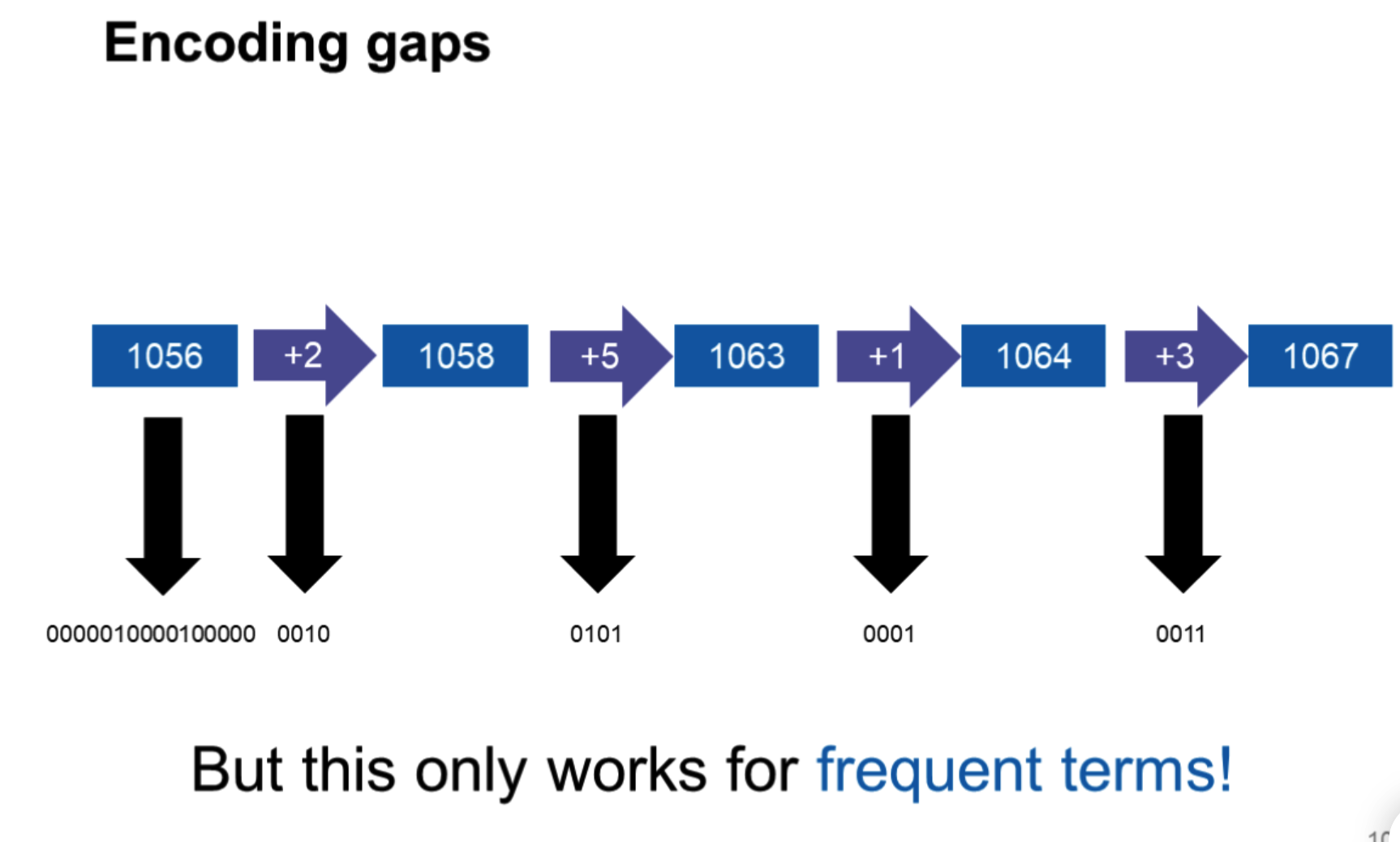
为什么要加文本频率? 便于进行词频的排序,利于后续查询优化
倒排索引布尔查询
略。并行课有涉及。比如当求交时可以先将短的链表求交。
倒排索引优化改进
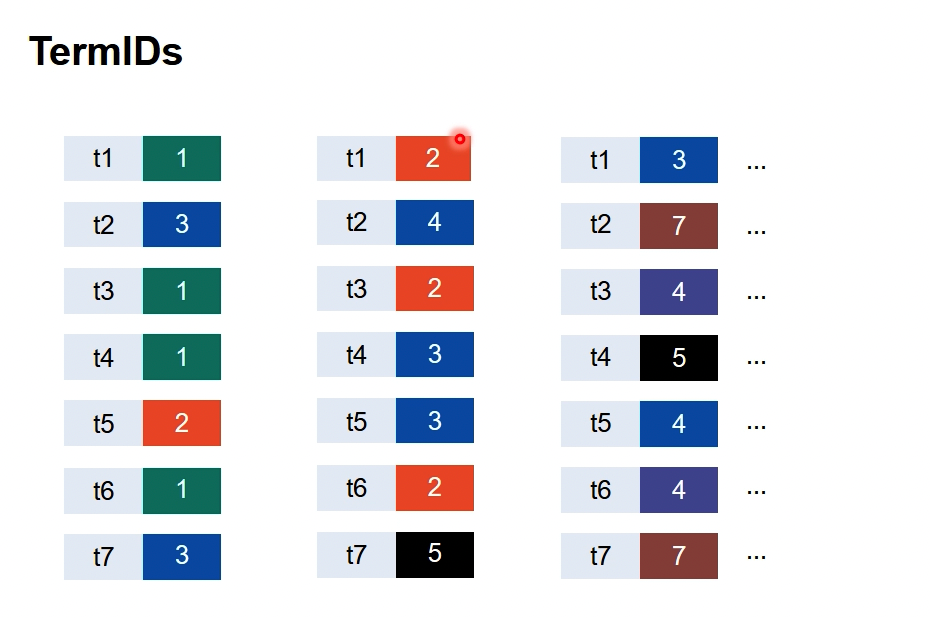
为了减少字符串所占用的内存,我们可以将键进行序列化。
Assume we have 1GB of text 800,000 documents 100 million tokens (Reuters-RCV1 collection)

(假设是用int存docID)

16*1.4
看上去很好。
然而,代价是必须要维护一张termID和字符串的映射表。
当需要处理的数据特别多时,由于排序,归并过程中所有的数据都需要这个表,就不得不一直将它放到内存里。
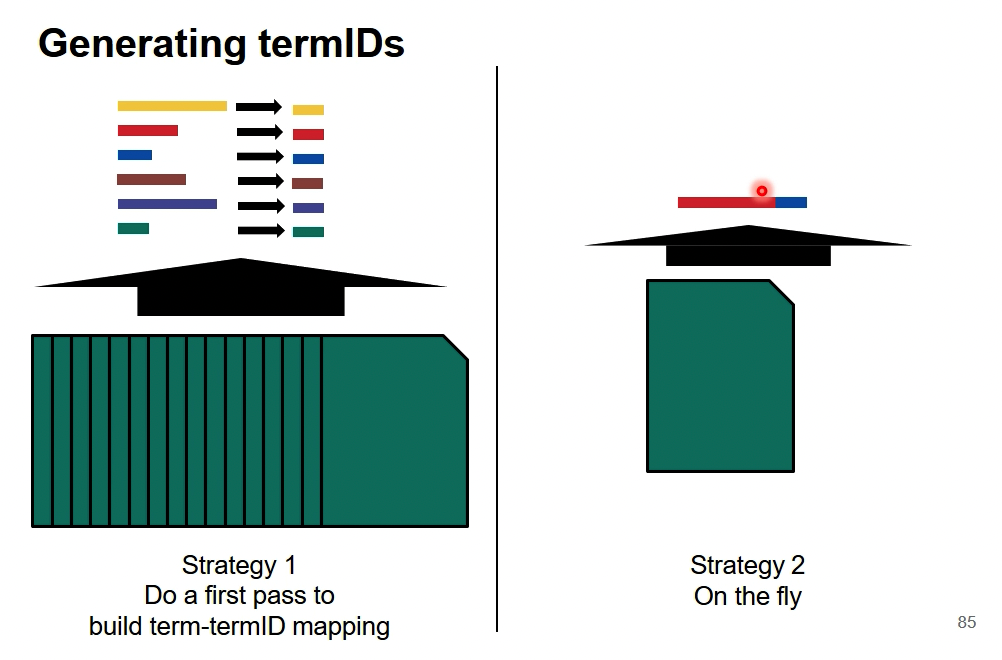
BSBI(Blocked Sort-Based Indexing)
仍然保留进行映射的策略
此算法的主要步骤如下:
1、将文档中的词进行id的映射,这里可以用hash的方法去构造
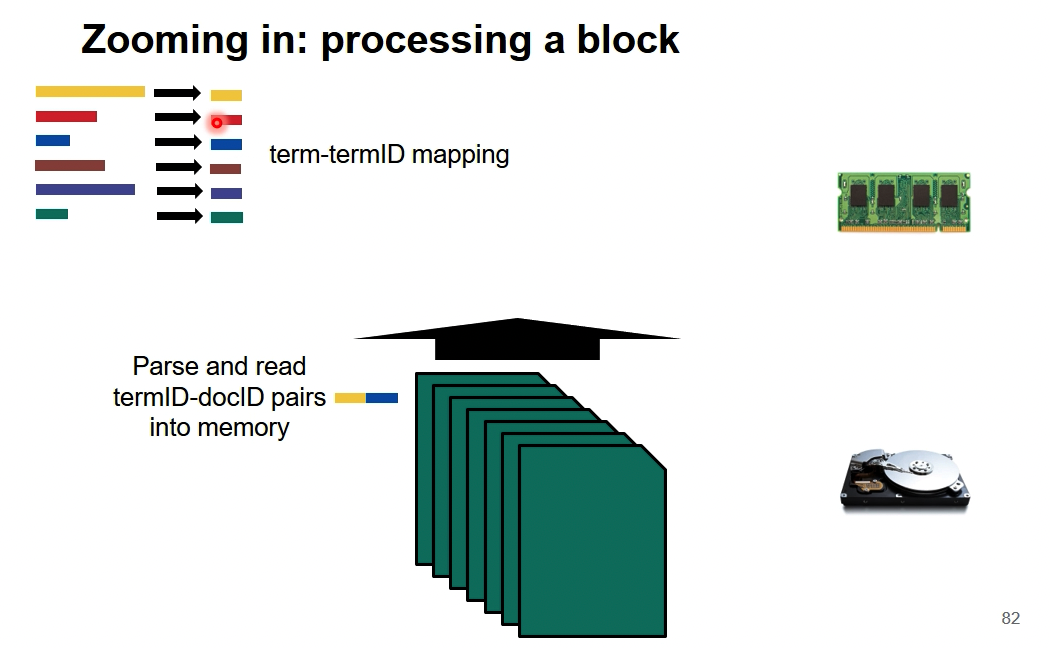
当然,可以先把全部文档读一遍构建映射,再分块构建倒排索引,也可以在构建每一块的倒排索引的时候边构建边映射。
2、将文档分割成大小相等的部分。分治

3、将每部分按照词ID对上文档ID的方式进行排序(保证分块可以在内存里放下)
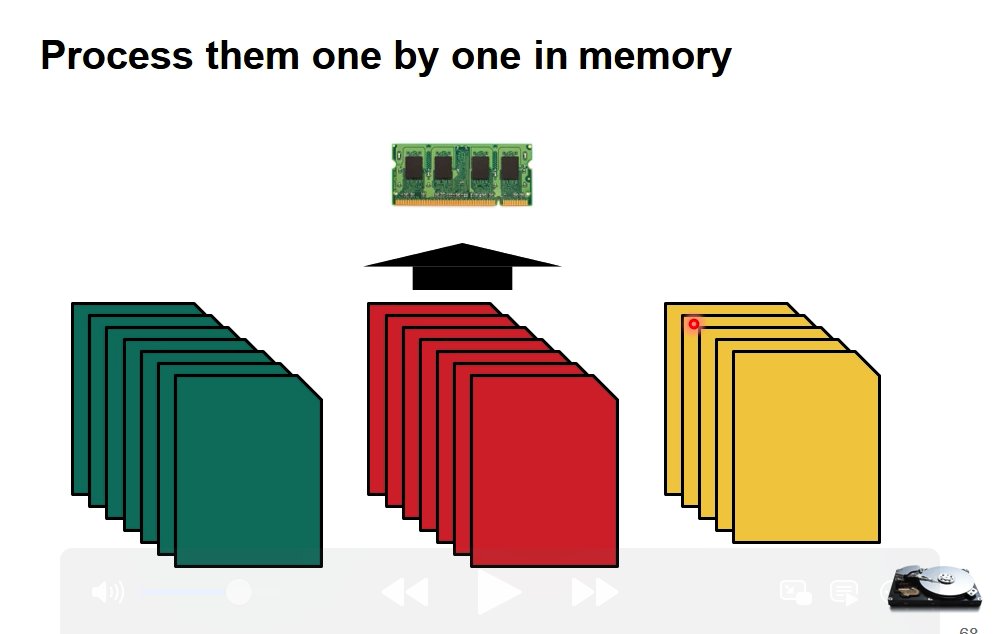
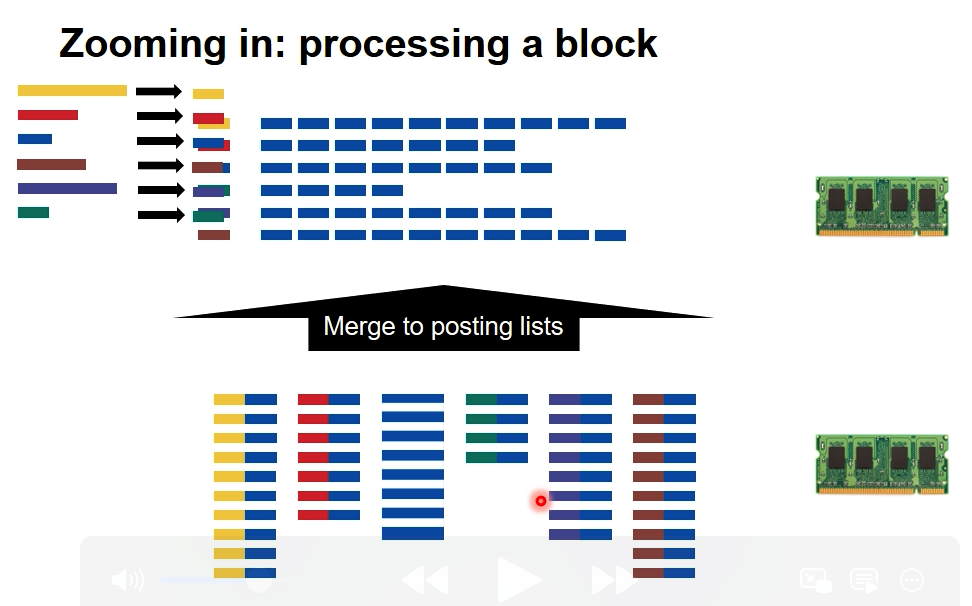
4、将每部分排序好后的结果进行合并,最后写出到磁盘中。
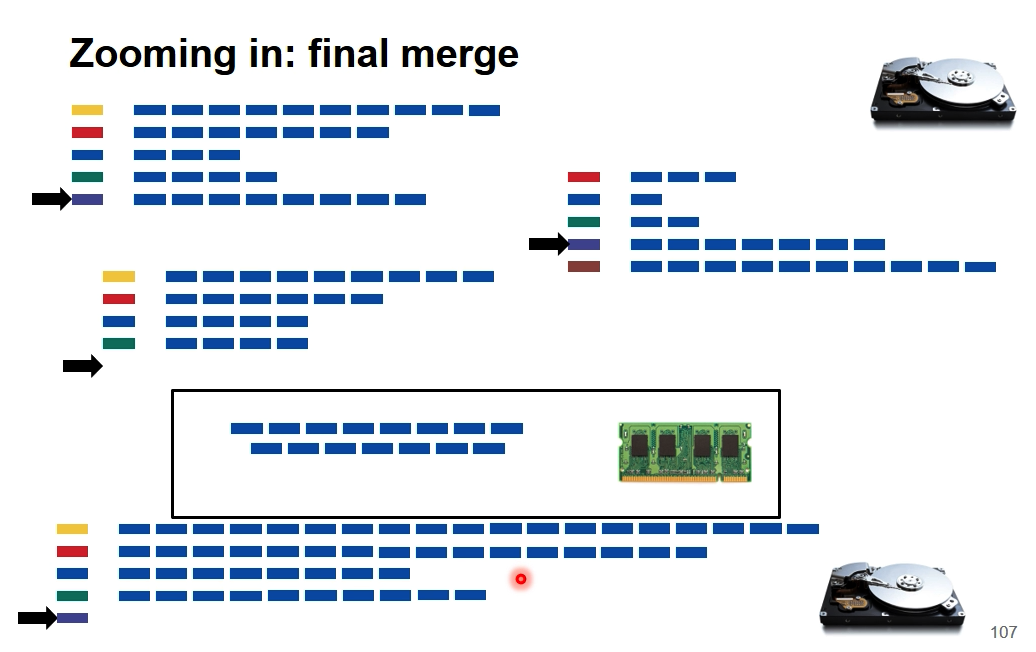
归并的过程中也可以分治,比如内存中只能放100个词条的总倒排索引,可以在第100个的时候写出磁盘(因为已经确定是最后结果了),从101个再继续。
SPIMI(Single-Pass In-Memory Indexing)
不作映射,其他与BSBI一样
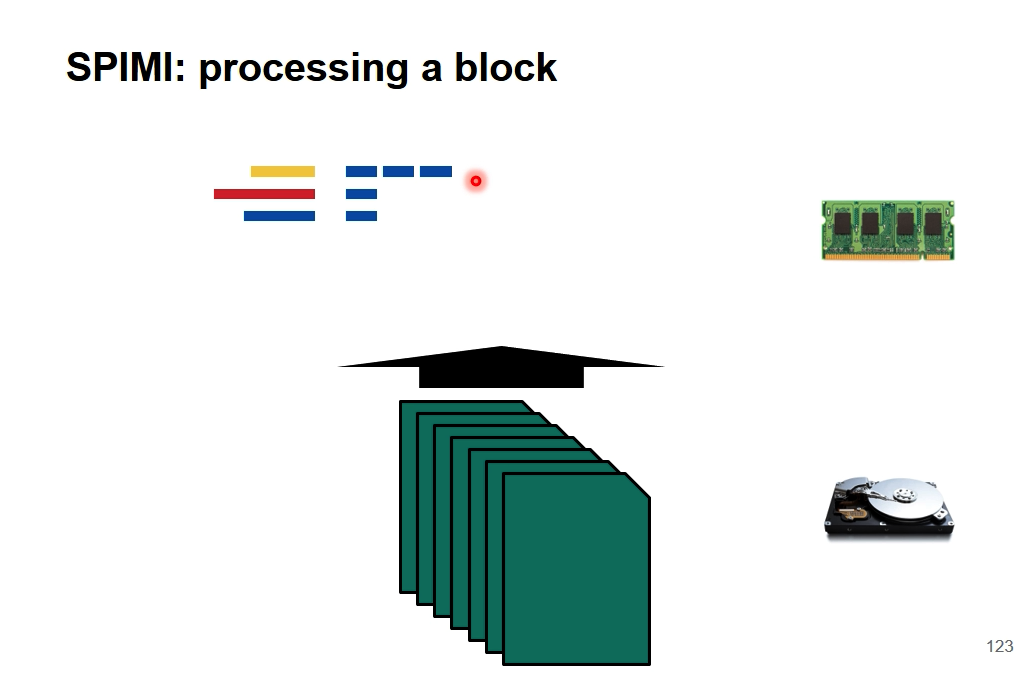
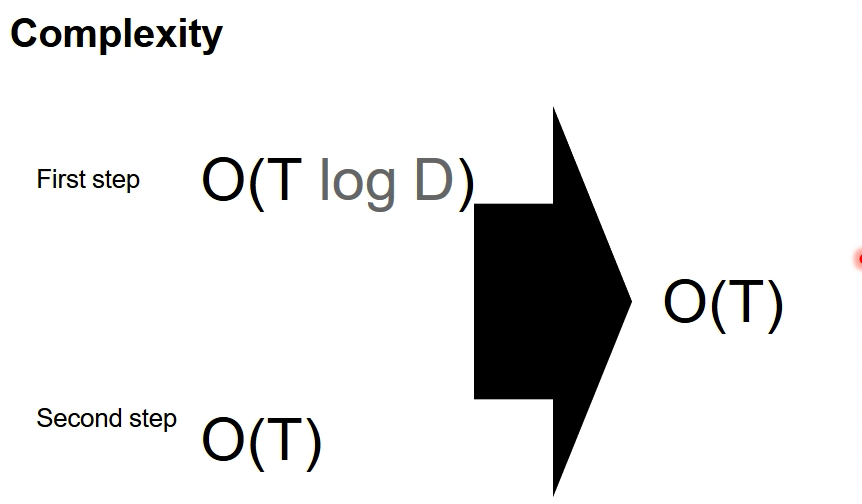
因为D显然要比T小的多
分布式解决方案MapReduce
大数据实训有涉及,略。
在线索引构建
朴素方案
朴素方案一:重建索引
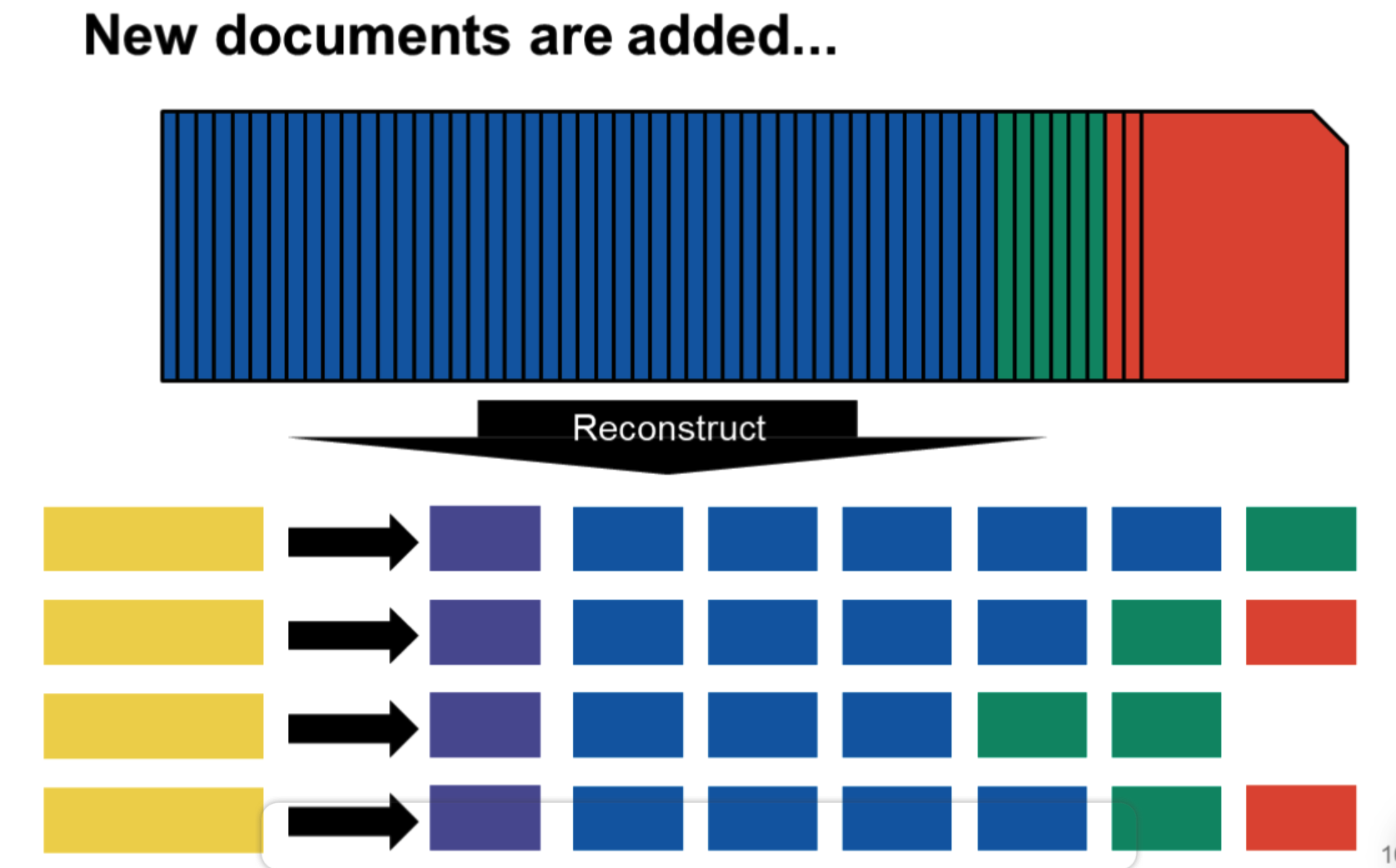
朴素方案二:辅助索引
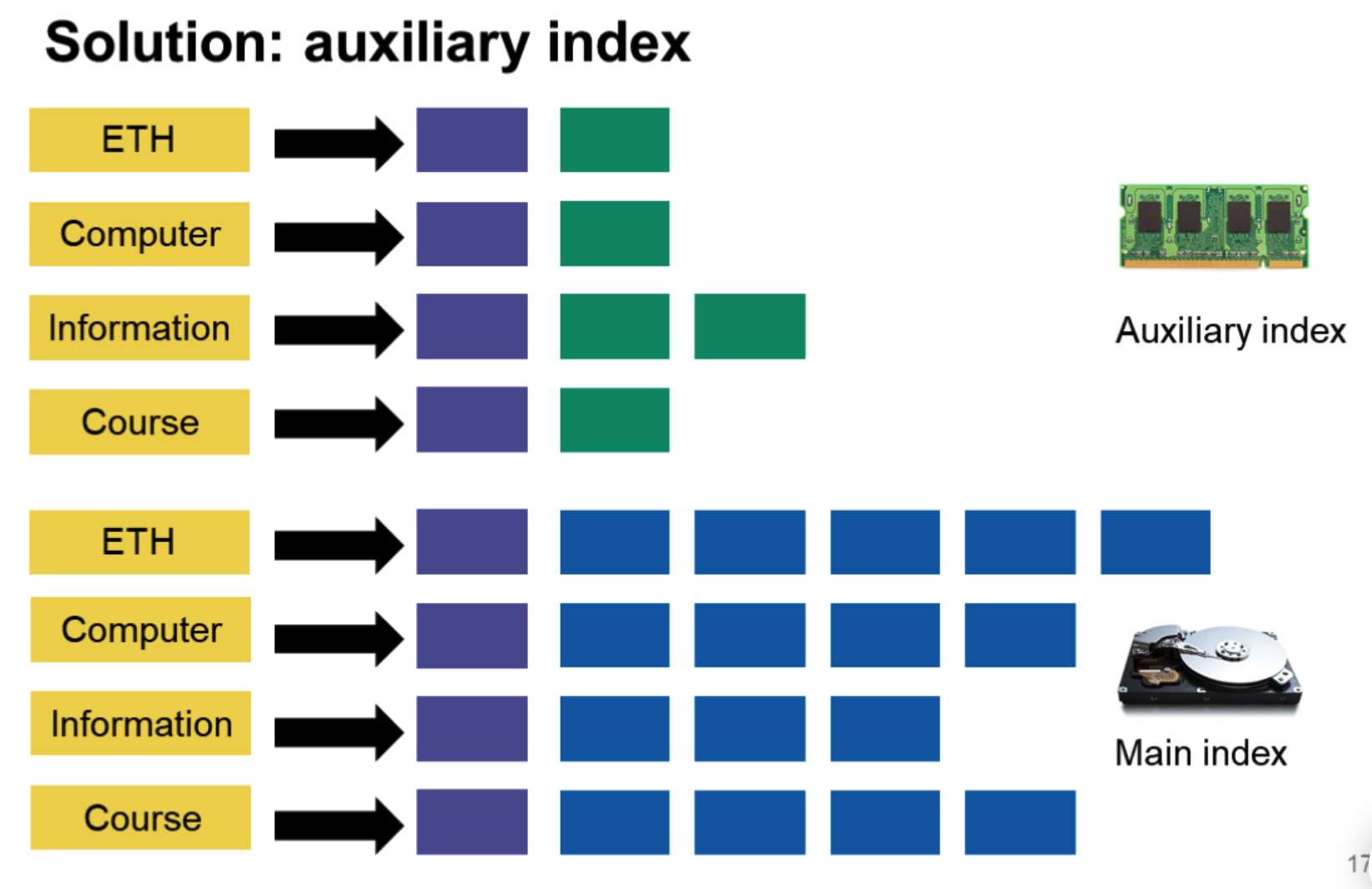
使用辅助索引的话,一个很简便的思路是一个词建一个文档,归并便变为两个文档的合并。
有什么缺陷?文件大小可能差距很大,且大量小文件不便于存储和对索引的快速读写(存储系统的问题)
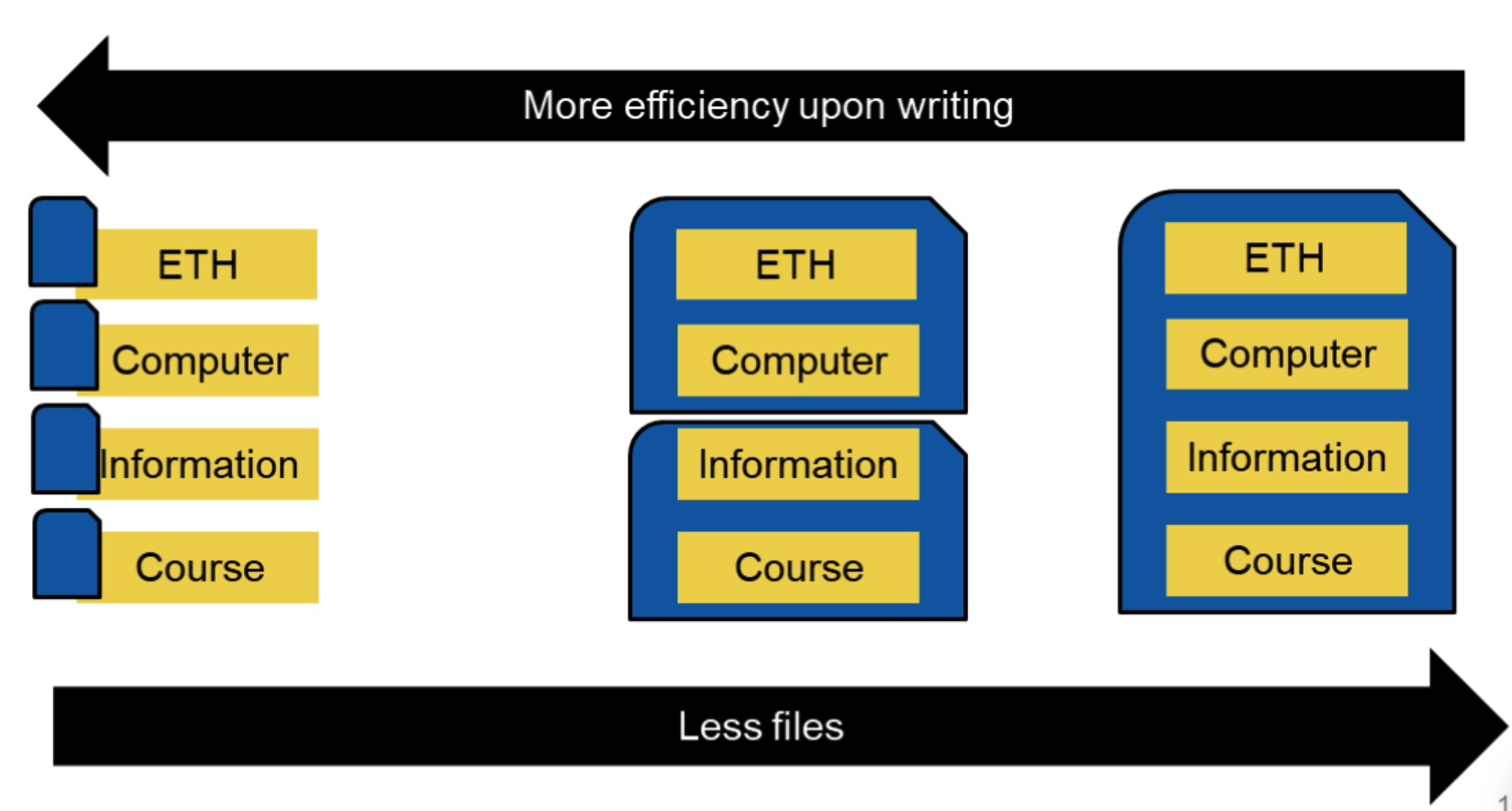
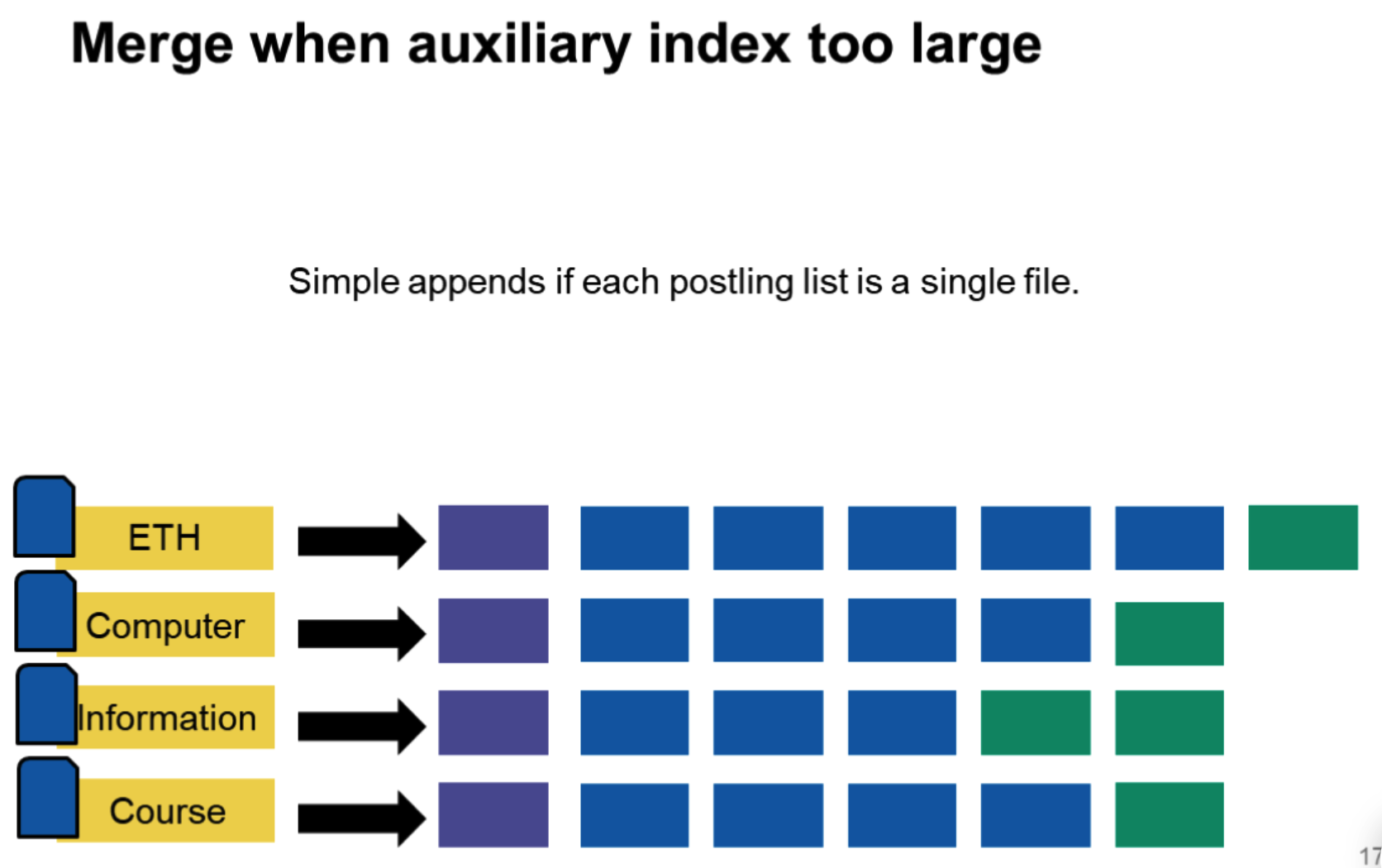
更大的问题,随着文档的数量变大,归并会越来越慢!
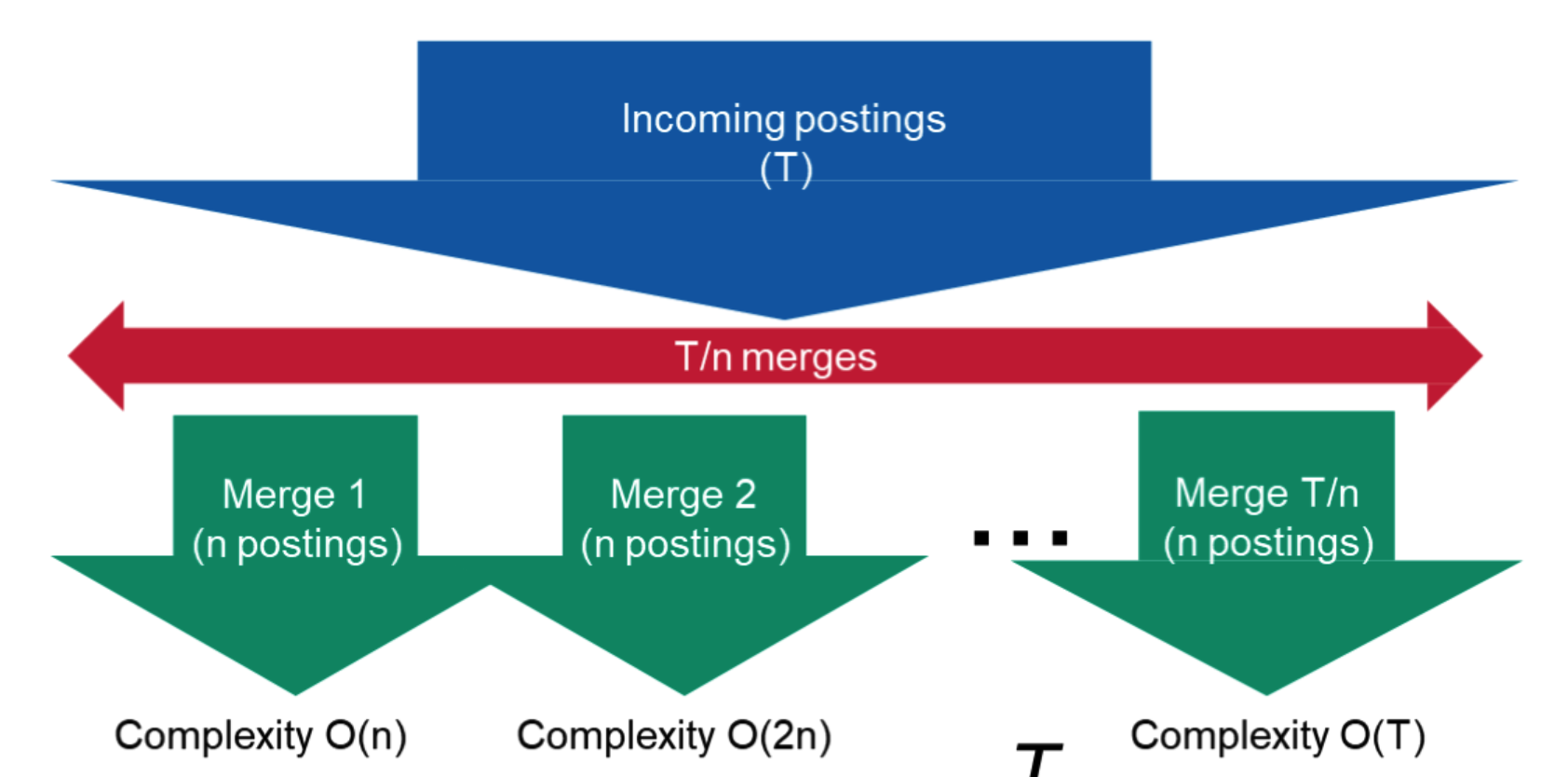
合并时termID是有序的,归并时类似于归并排序,最坏复杂度是较大的那个索引的termID个数。而单个倒排索引合并只需要把新的list放到旧的后面就可以了,因为新的list中的docID肯定会比旧的大(就像上面图上所示) \[ O\left(n+2n+\ldots+\frac{T}{n}\right)=O\left(\frac{T^2}{n}\right) \]
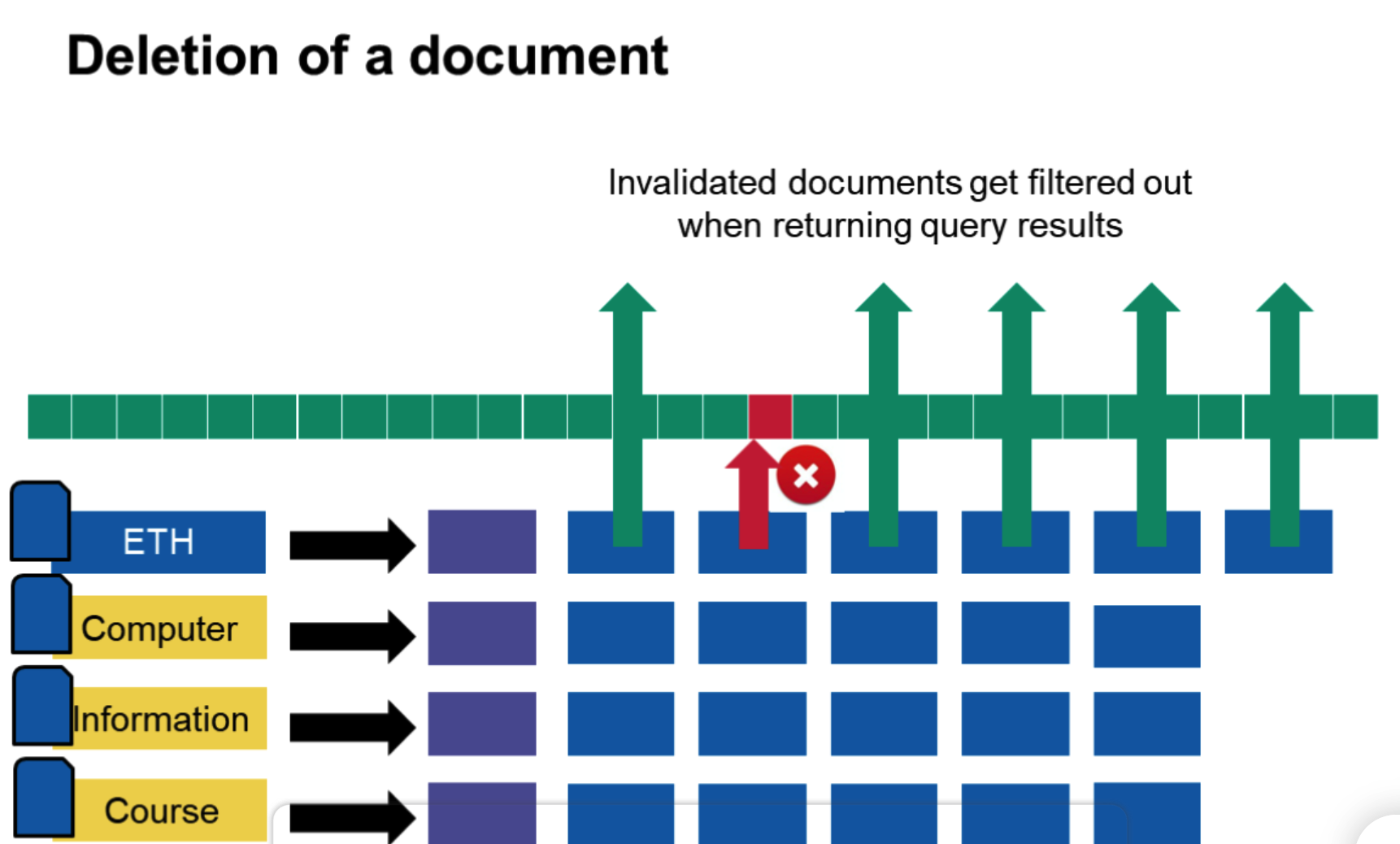
文档删除怎么操作?
无效向量
倒排索引压缩
一些朴素的偷懒方法
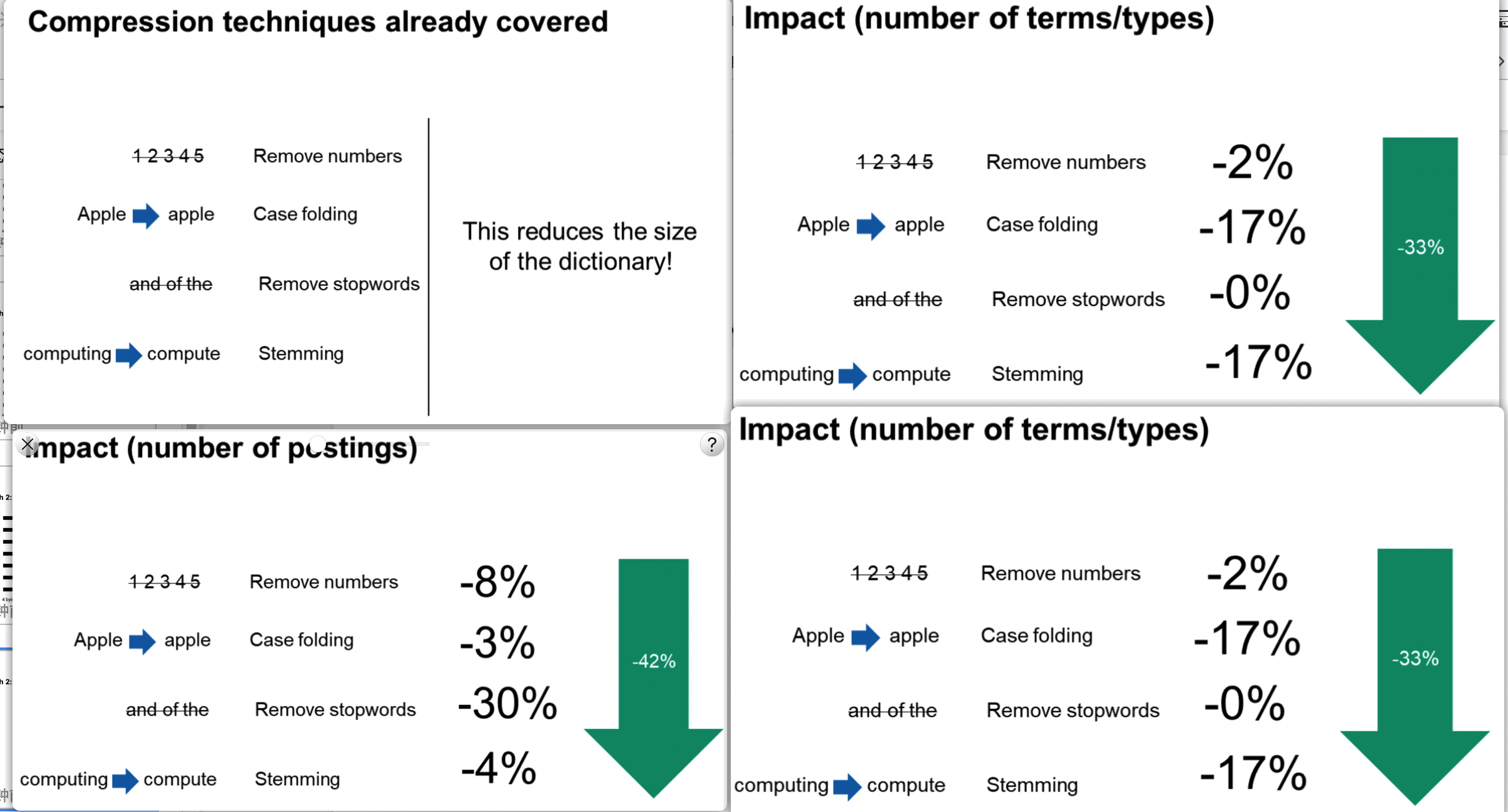
但是现代检索系统一般不会这么做,因为会导致一些信息的丢失。
词典压缩
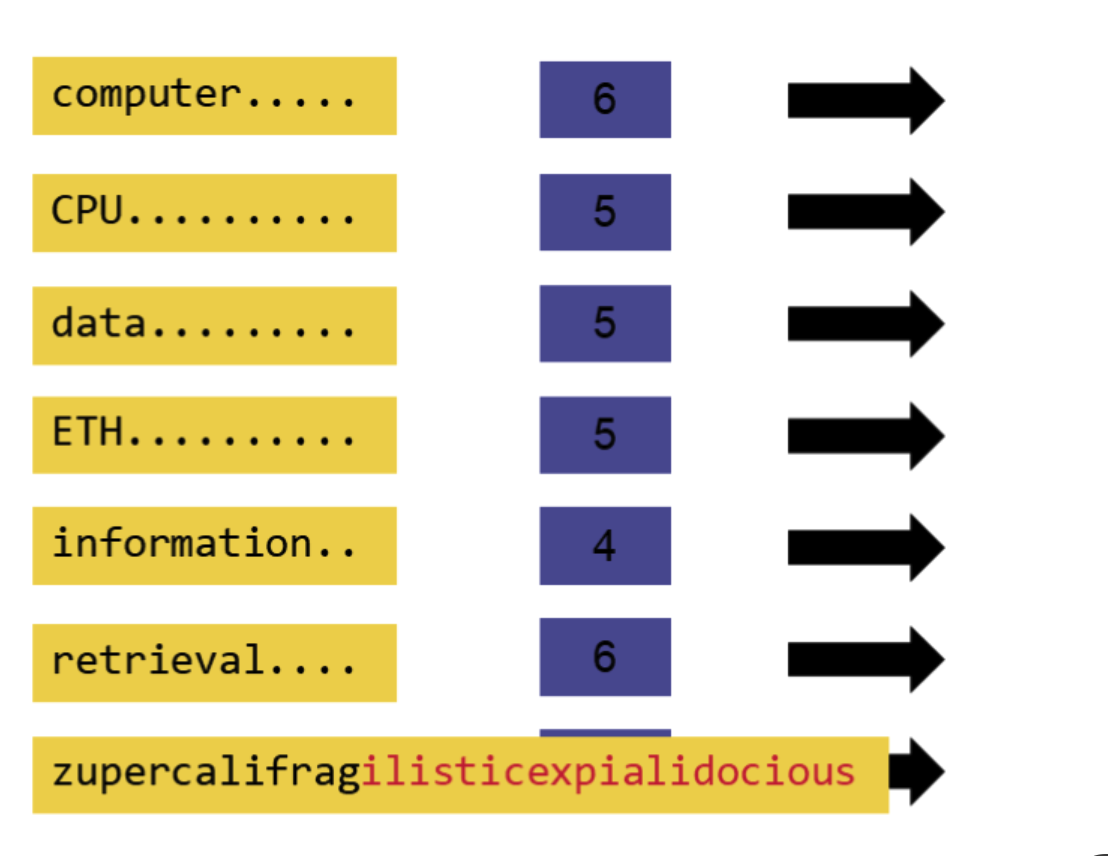
方法一:使用数组
是一种很蠢的方法
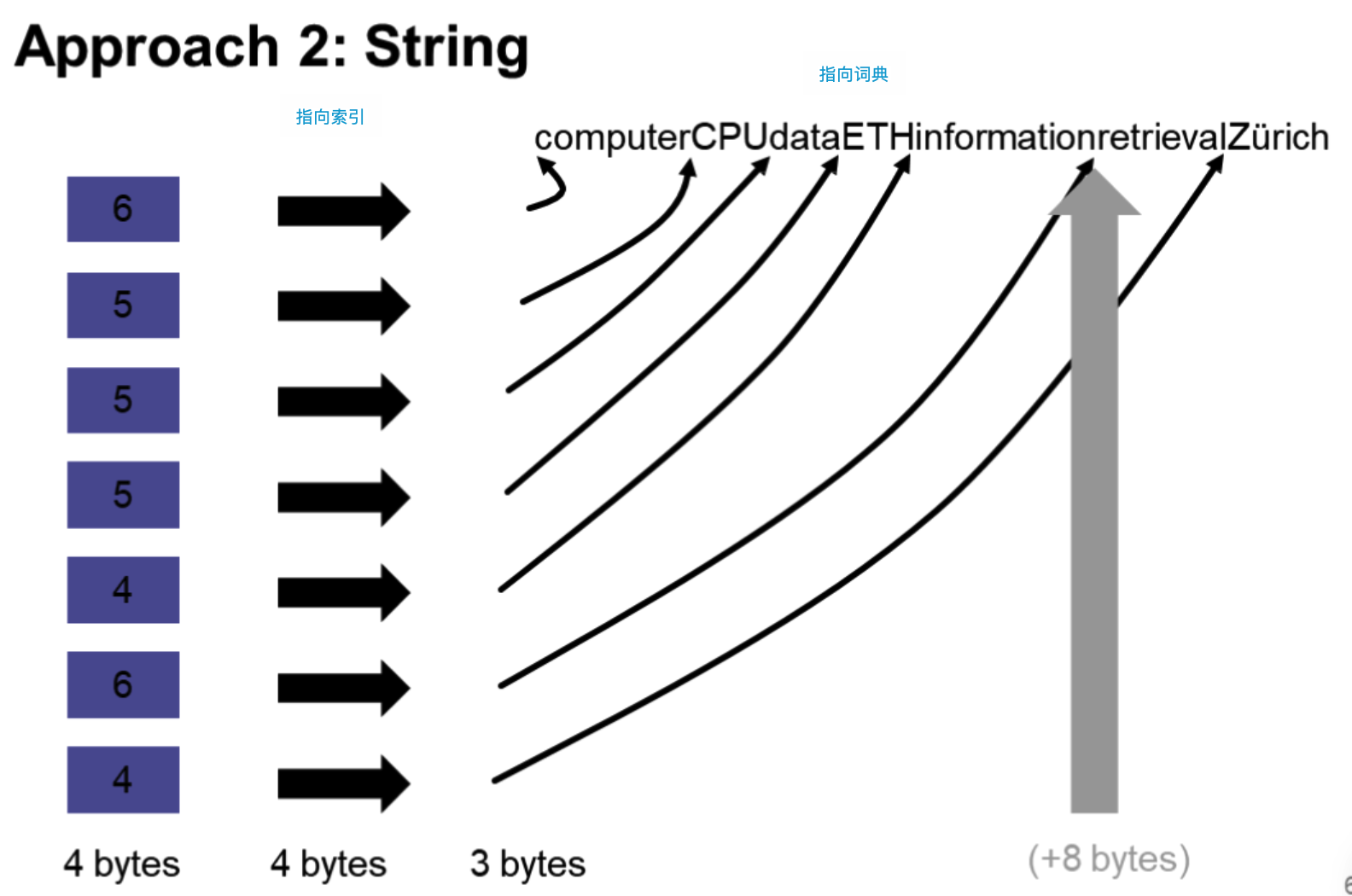
方法二:指针
方法二的优化:分段指针
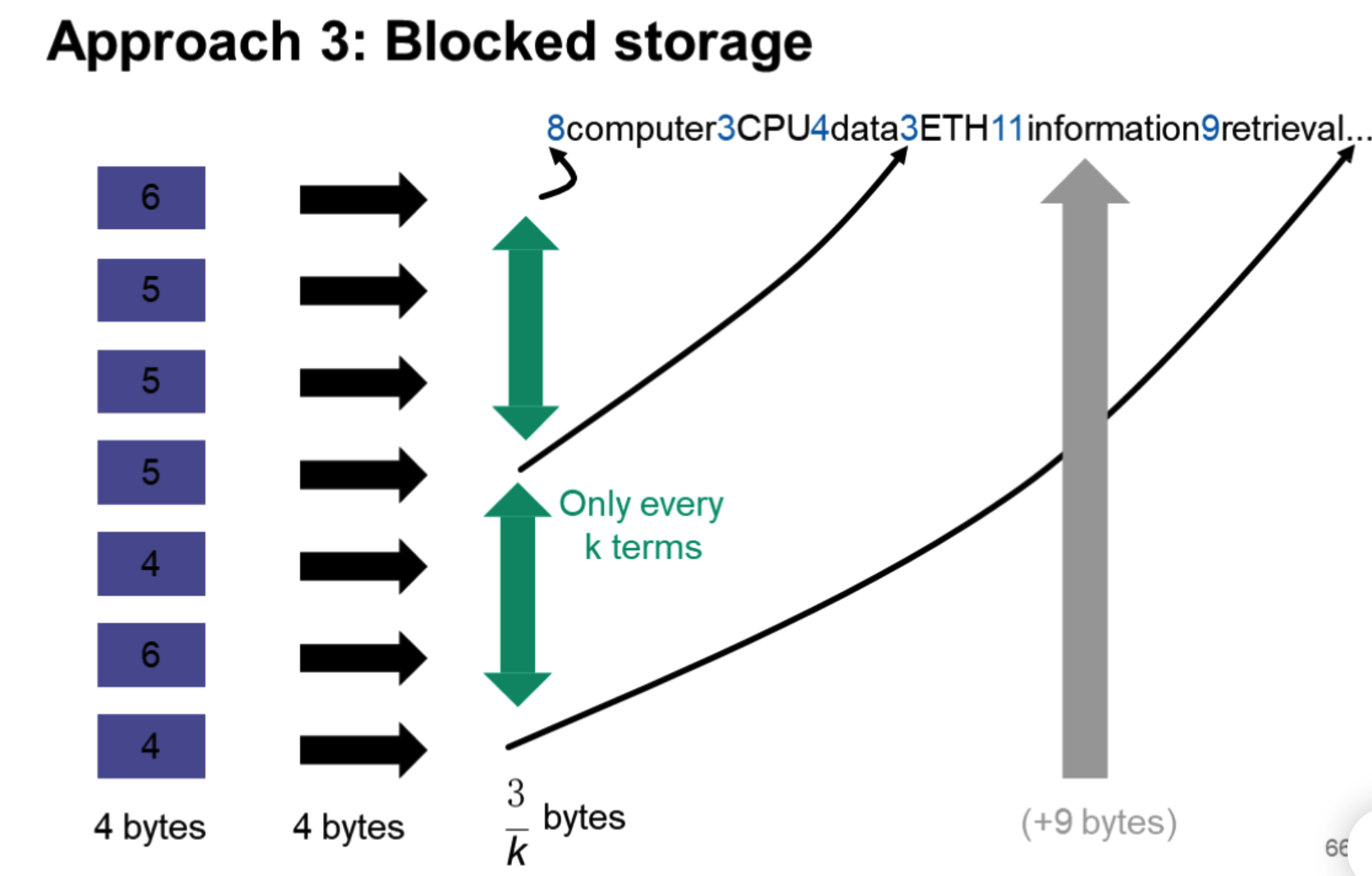
当然,找termID对应的词项会慢一些。
采用前缀的方式
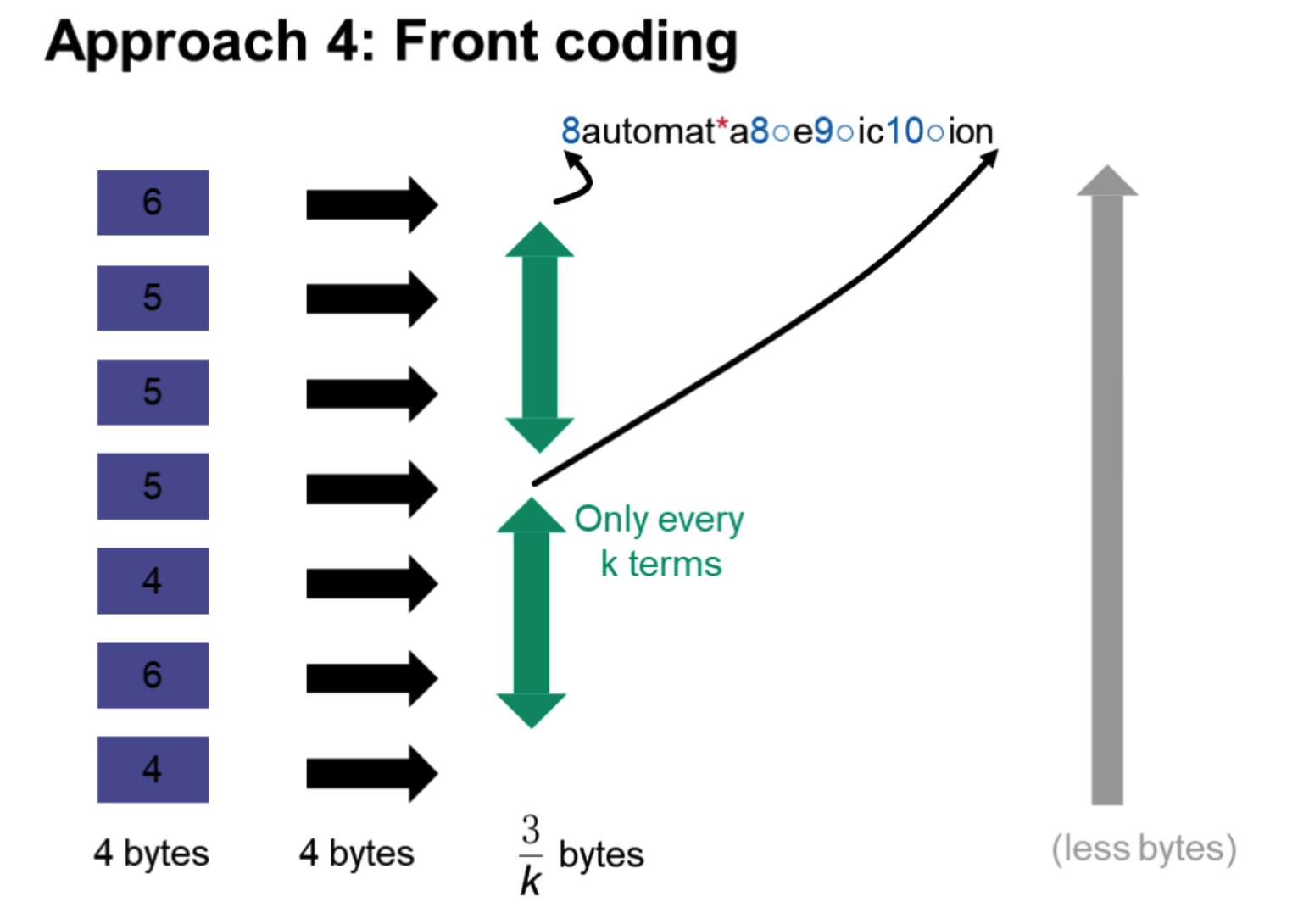
索引表压缩
Encoding gaps
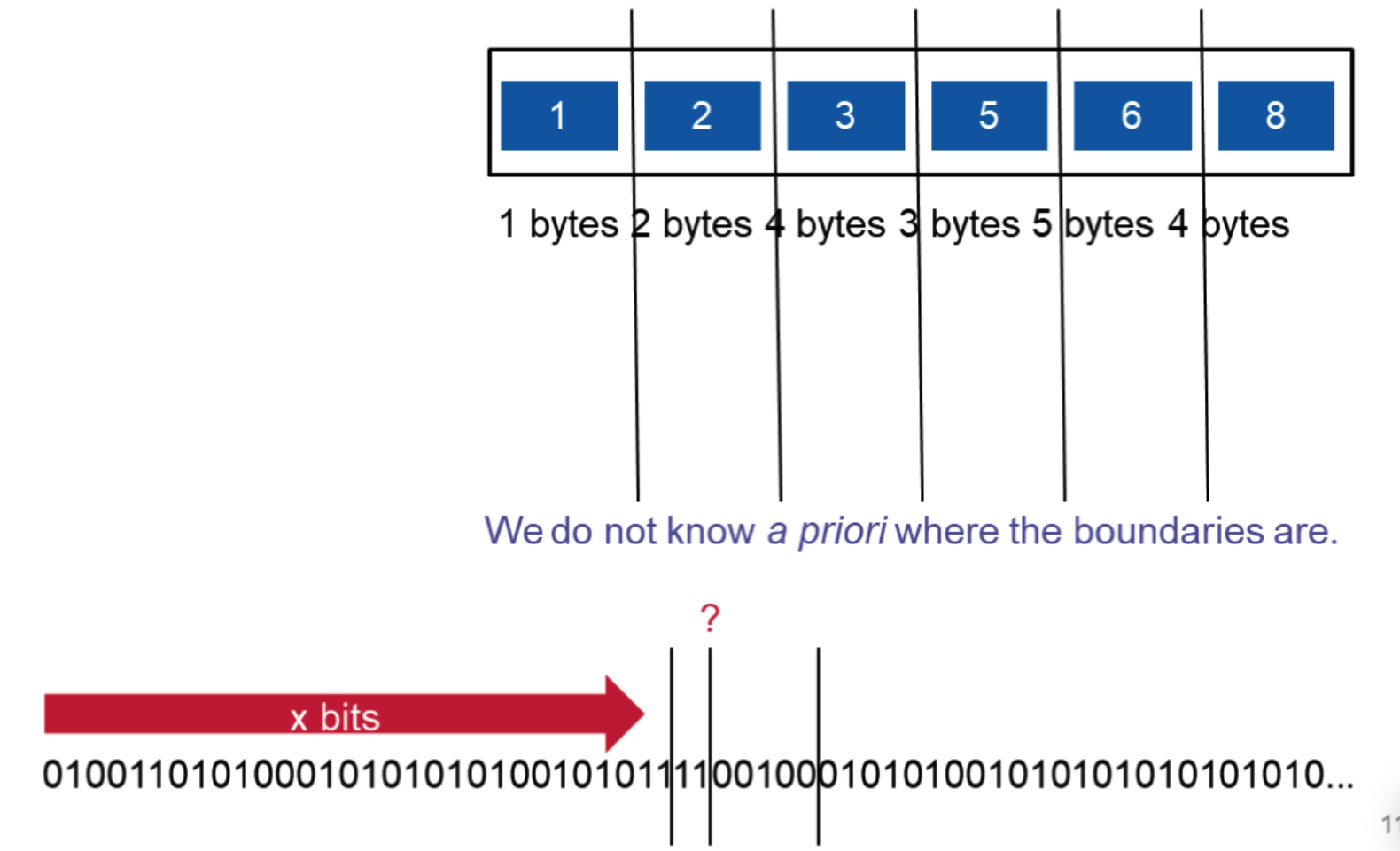
Variable length codings
例子:可变长UTF-8
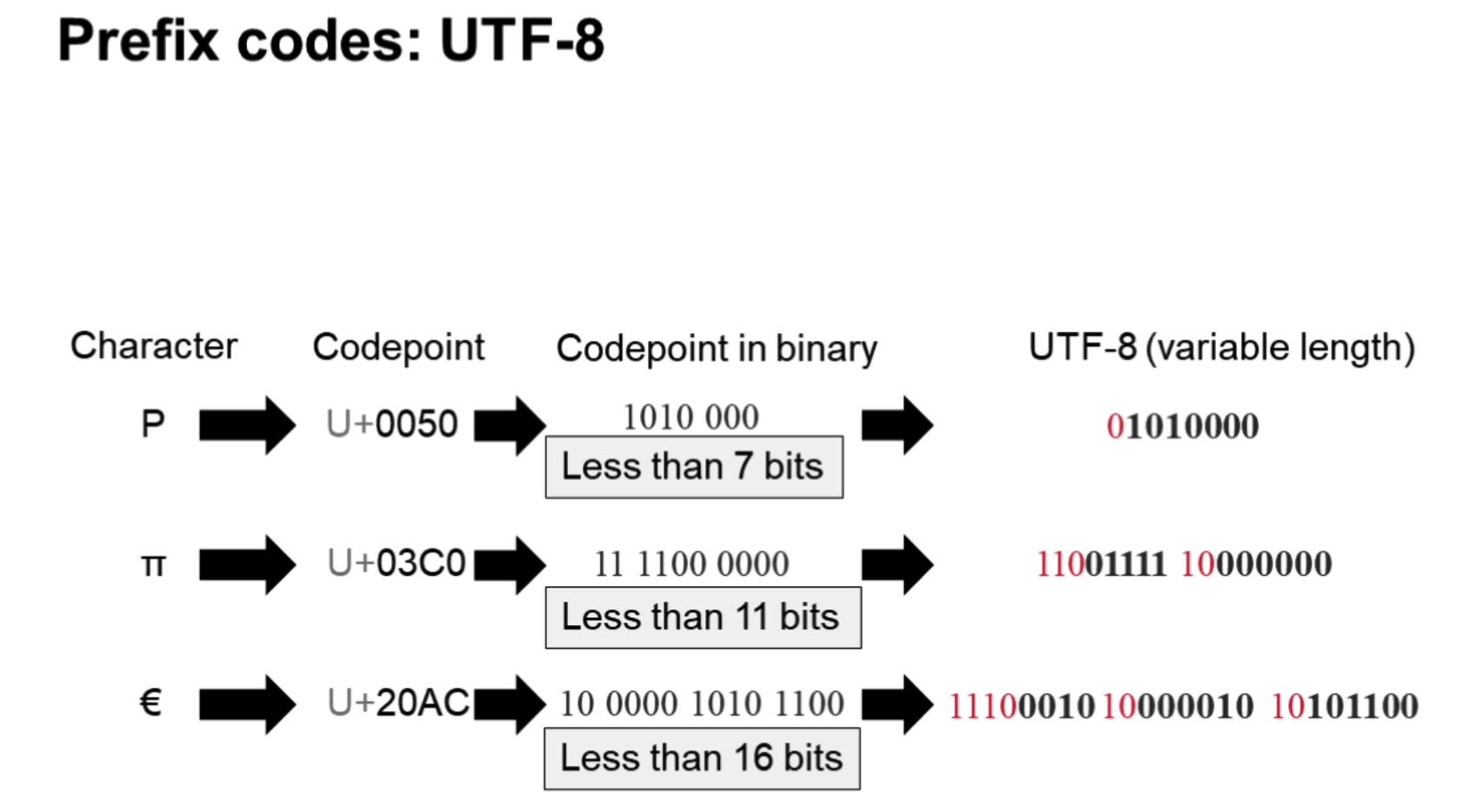
UTF-8 的编码规则很简单,只有二条:
1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的
Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的。
2)对于n字节的符号(n > 1),第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的
Unicode 码。
下表总结了编码规则,字母x表示可用编码的位。
Unicode符号范围 | UTF-8编码方式
(十六进制) | (二进制)
-------------------+---------------------------------------------
0000 0000-0000 007F | 0xxxxxxx
0000 0080-0000 07FF | 110xxxxx 10xxxxxx
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx根据上表,解读 UTF-8
编码非常简单。如果一个字节的第一位是0,则这个字节单独就是一个字符;如果第一位是1,则连续有多少个1,就表示当前字符占用多少个字节。
下面,以汉字严为例,演示如何实现 UTF-8 编码。
严的 Unicode
是4E25(100111000100101),根据上表,可以发现4E25处在第三行的范围内(0000 0800 - 0000 FFFF),因此严的
UTF-8
编码需要三个字节,即格式是1110xxxx 10xxxxxx 10xxxxxx。然后,从严的最后一个二进制位开始,依次从后向前填入格式中的x,多出的位补0。这样就得到了,严的
UTF-8
编码是11100100 10111000 10100101,转换成十六进制就是E4B8A5。
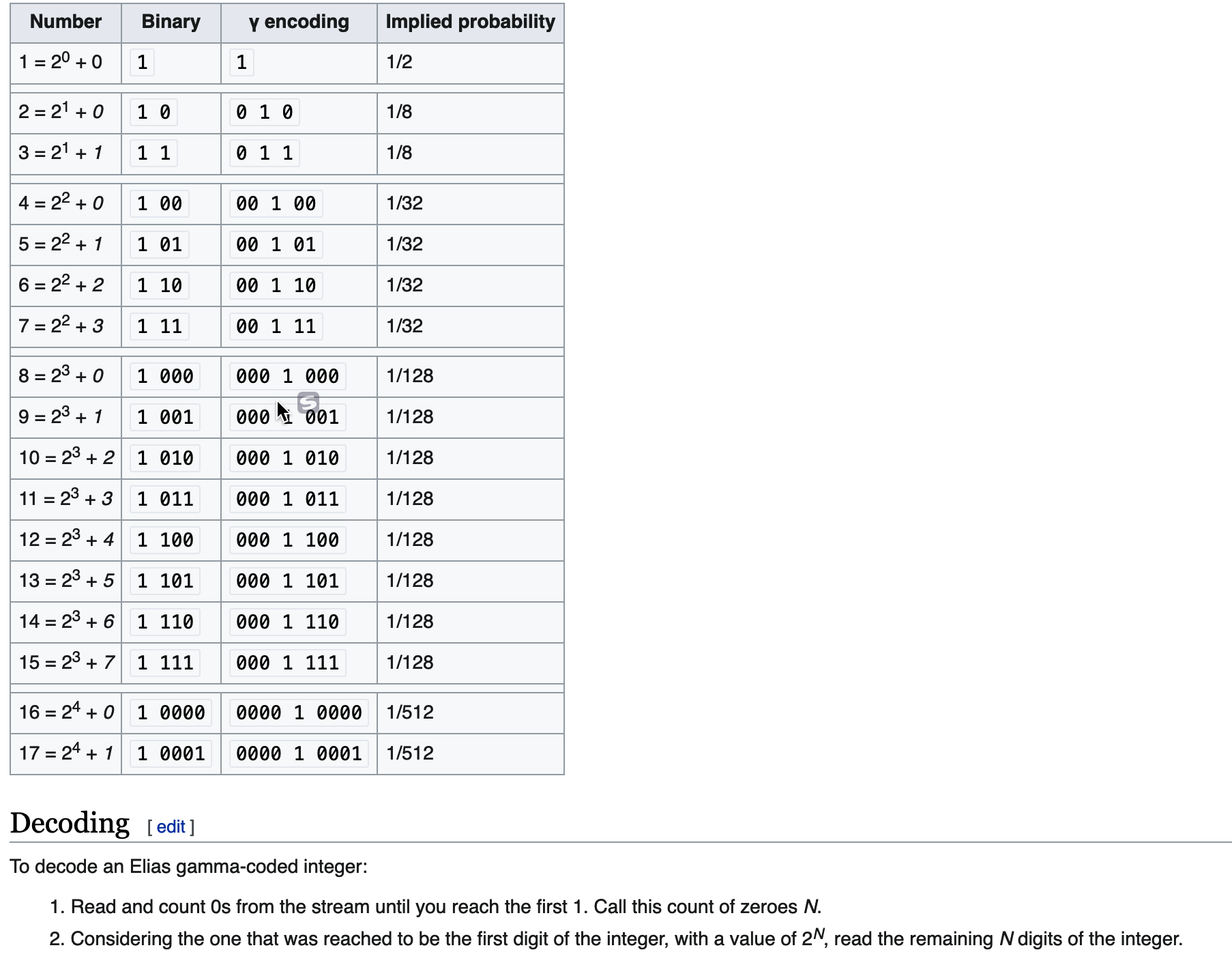
Gamma Encoding
根据维基百科所述,gamma编码过程如下图所示。虽具体过程与课上讲述稍有不同,但原理是一样的。

编码具体案例和解码过程。
查询优化
倒排索引数据结构优化
“跳表”
动机
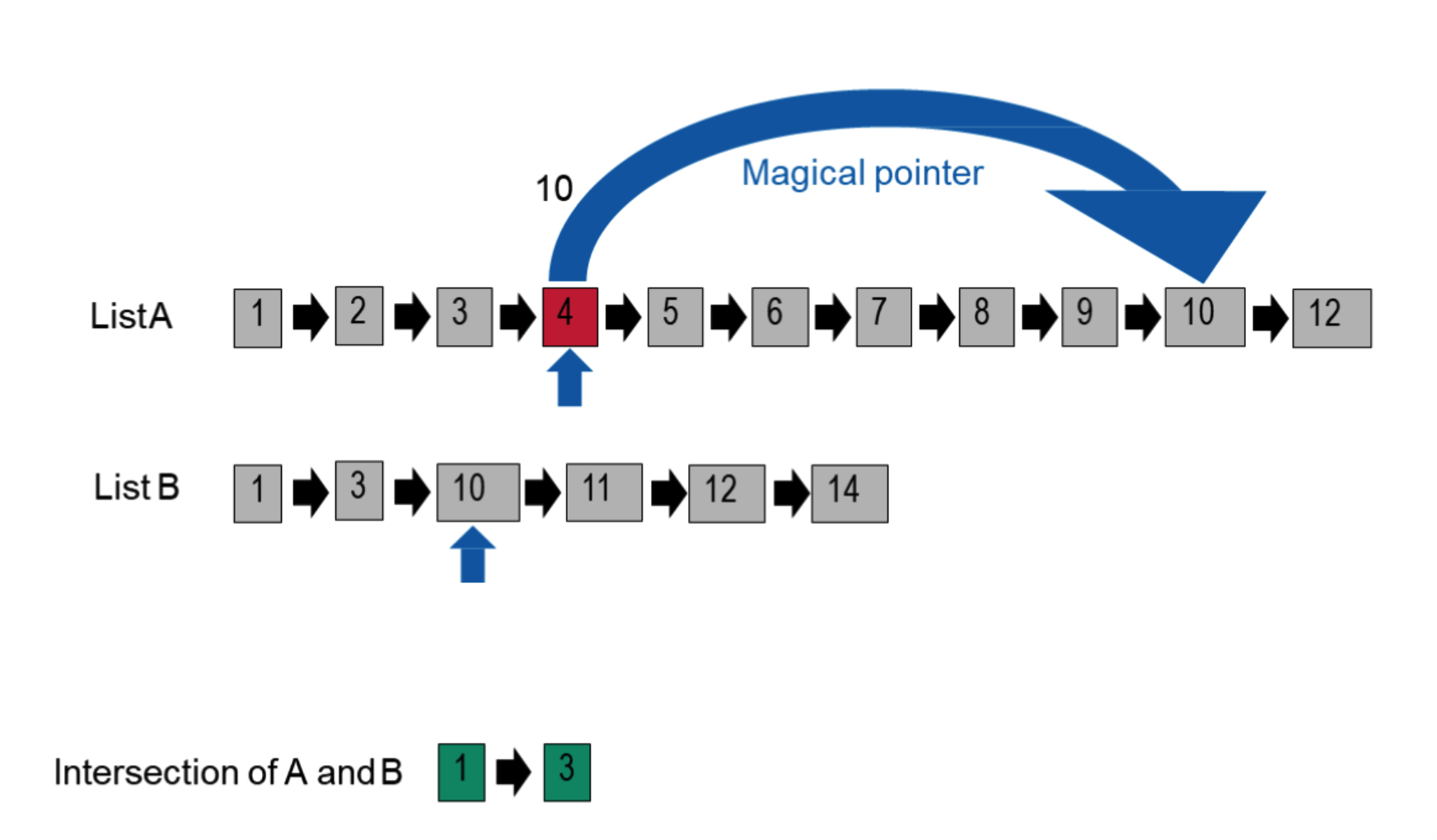
怎么选取间隔?“摔瓶子”。开根号
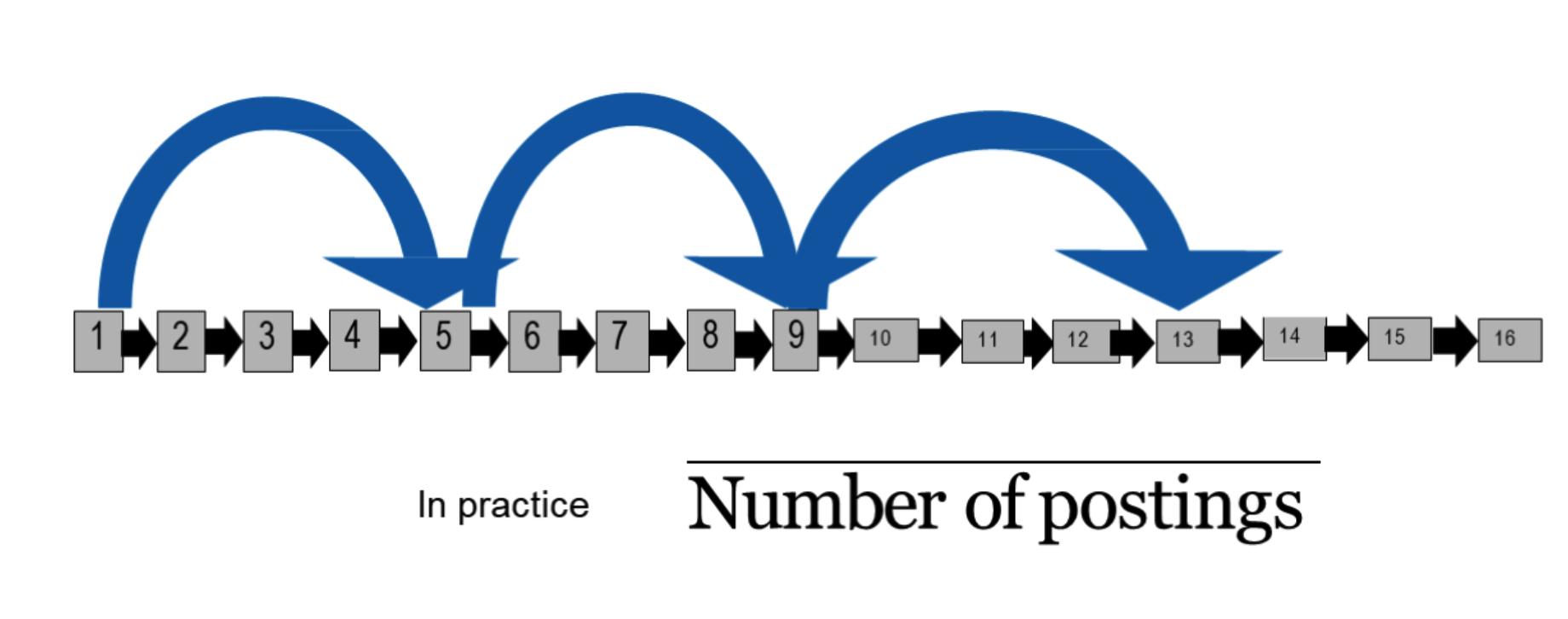
实例:

为什么是先跳再判断,如果跳过了再倒回去,而不是比较之后再跳?后者比较次数太多,开销大,且慢。
词项数据结构
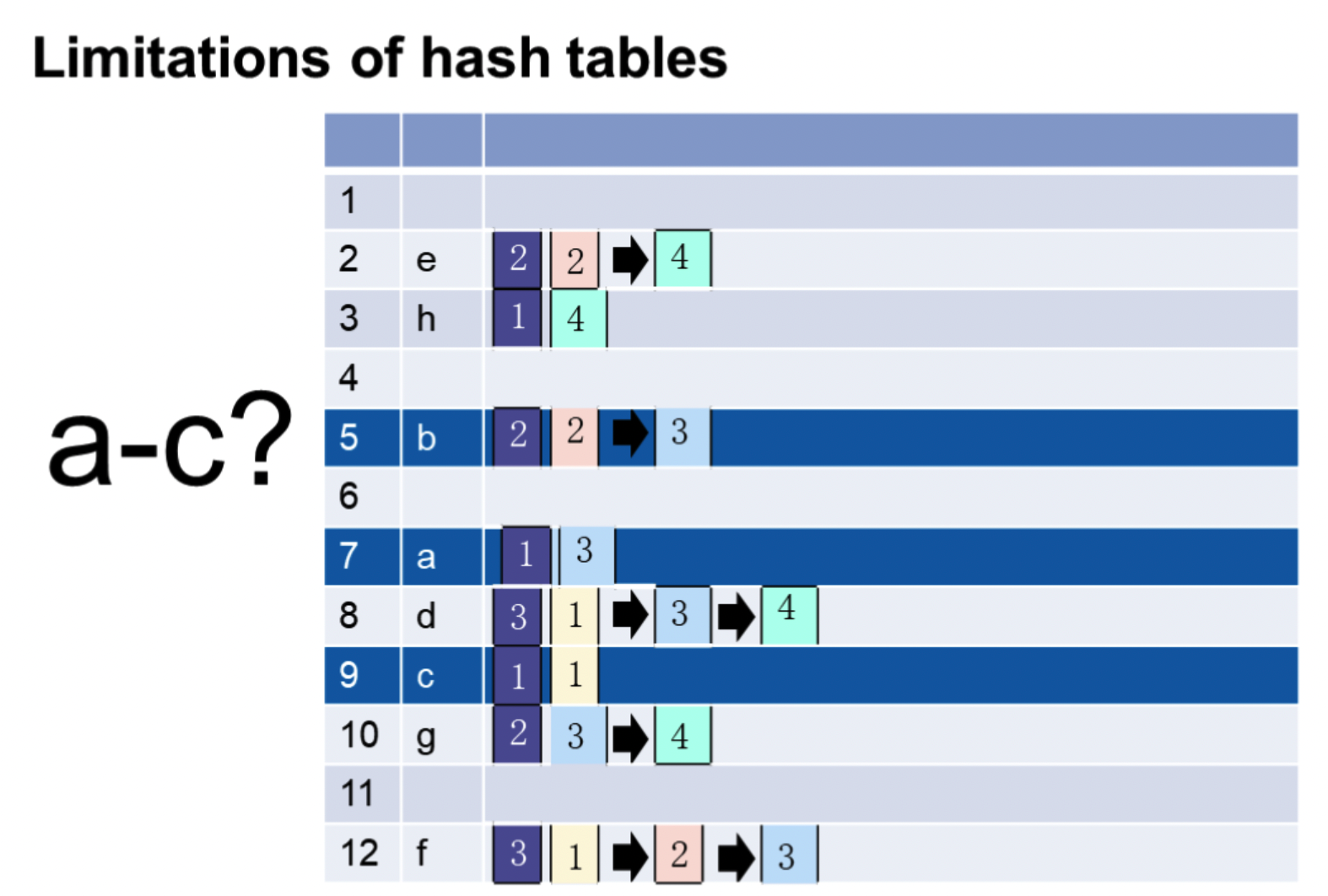
哈希表
优点:快
缺点:不支持模糊查询
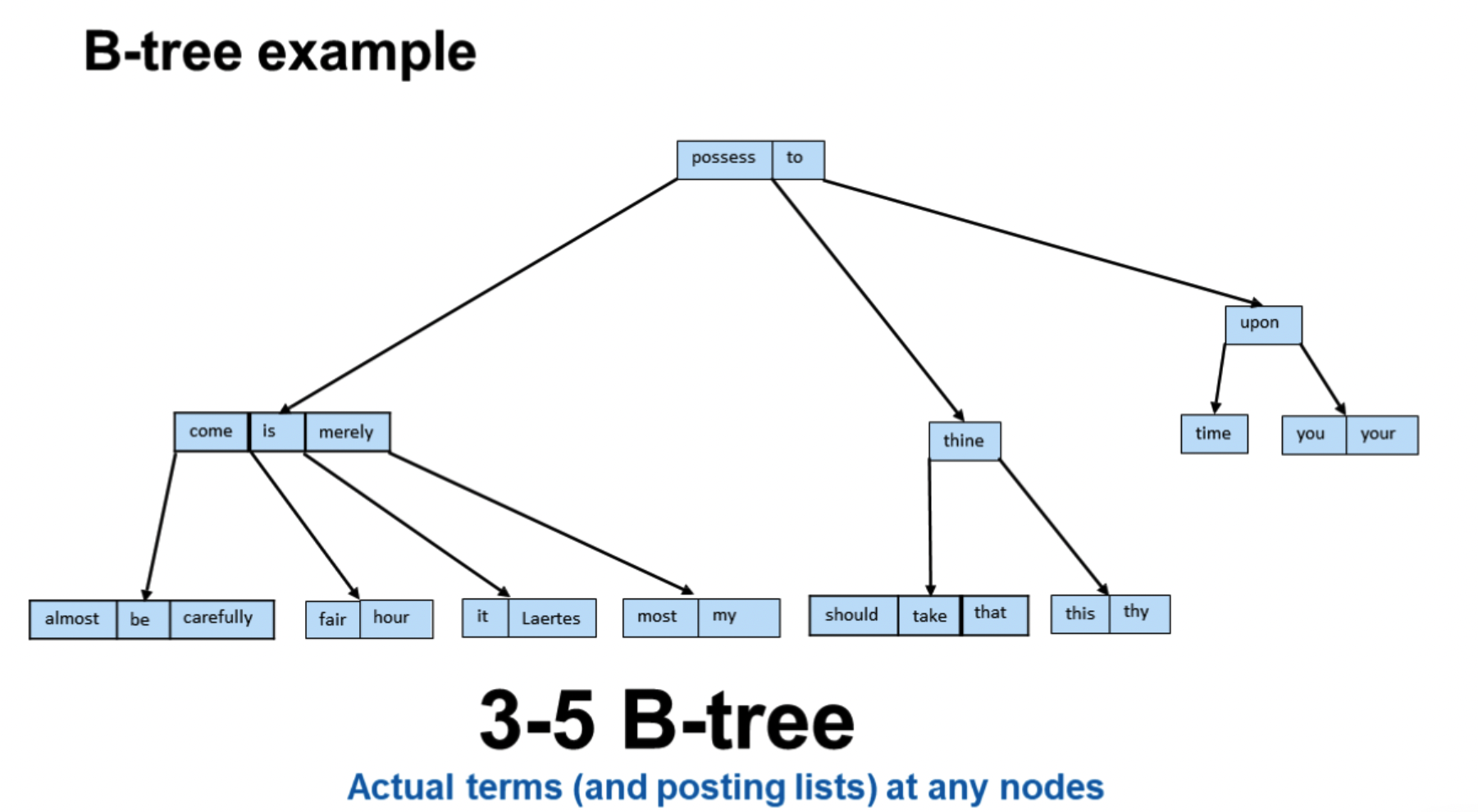
B树
实际使用
通配符查询支持
前缀:B树天然支持
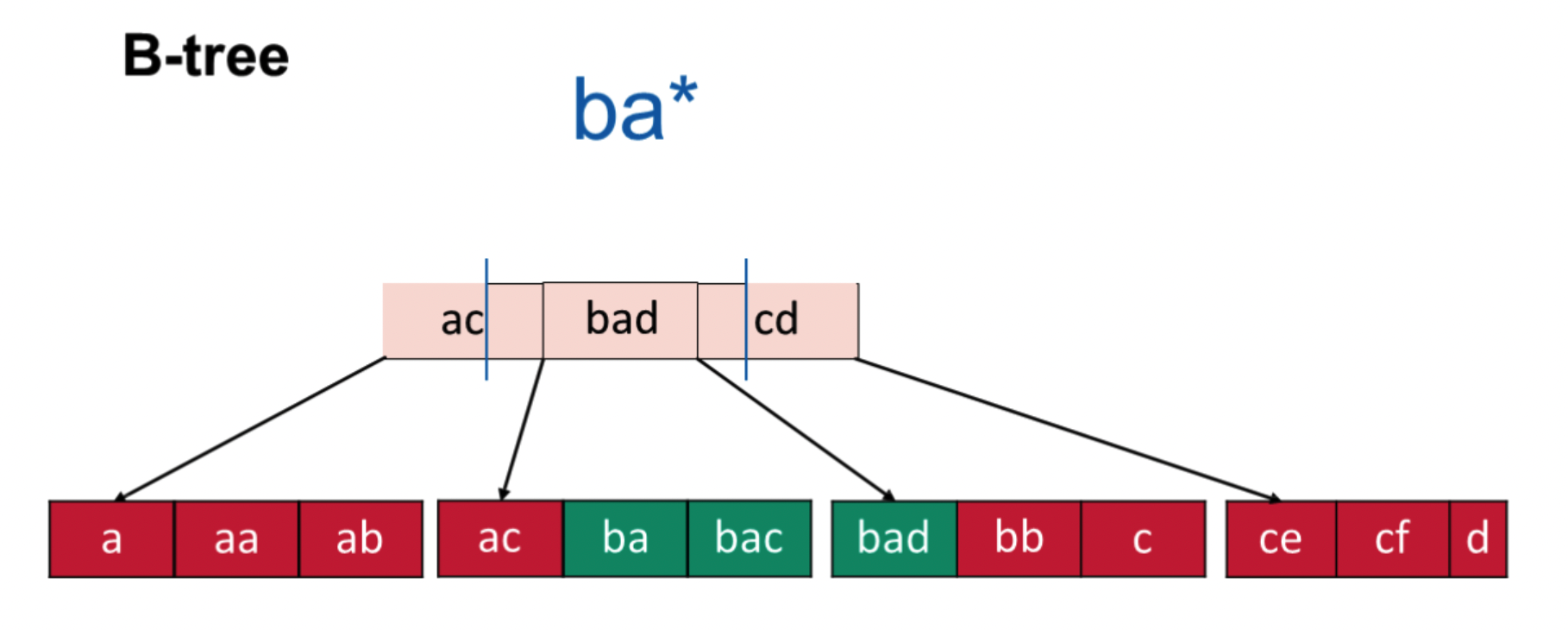
后缀:对逆序建B树
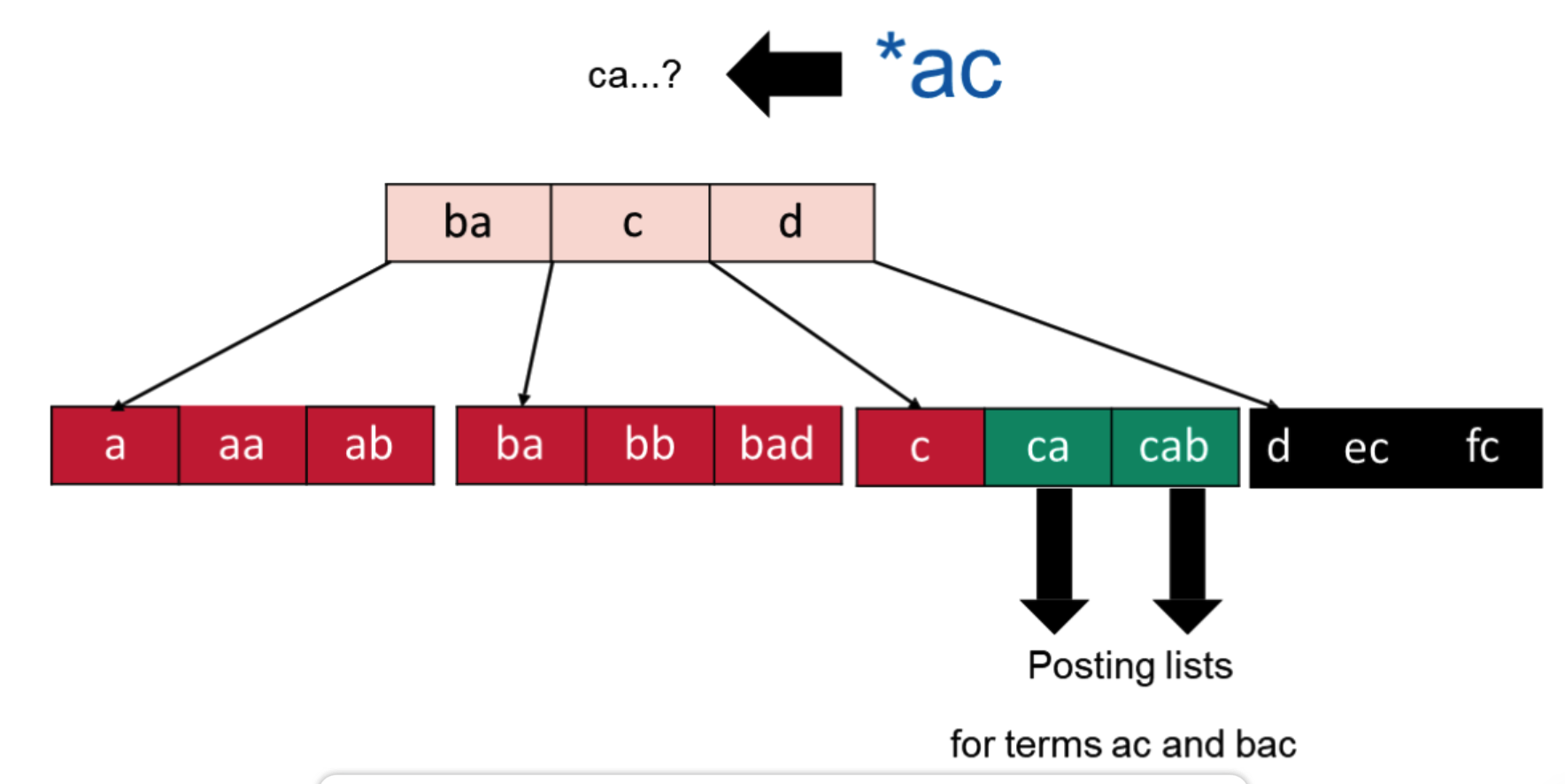
中间的?好像有点问题。。。

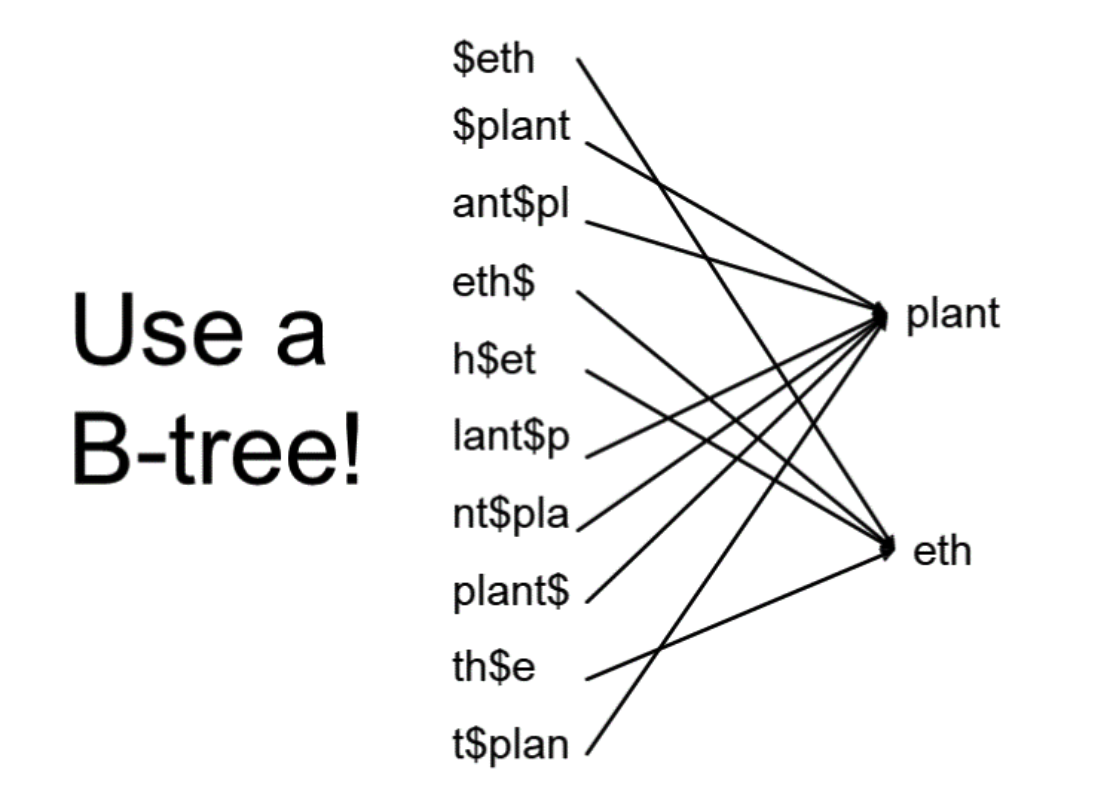
轮排索引

采用B树。但通常这种方法产生的B树会非常大
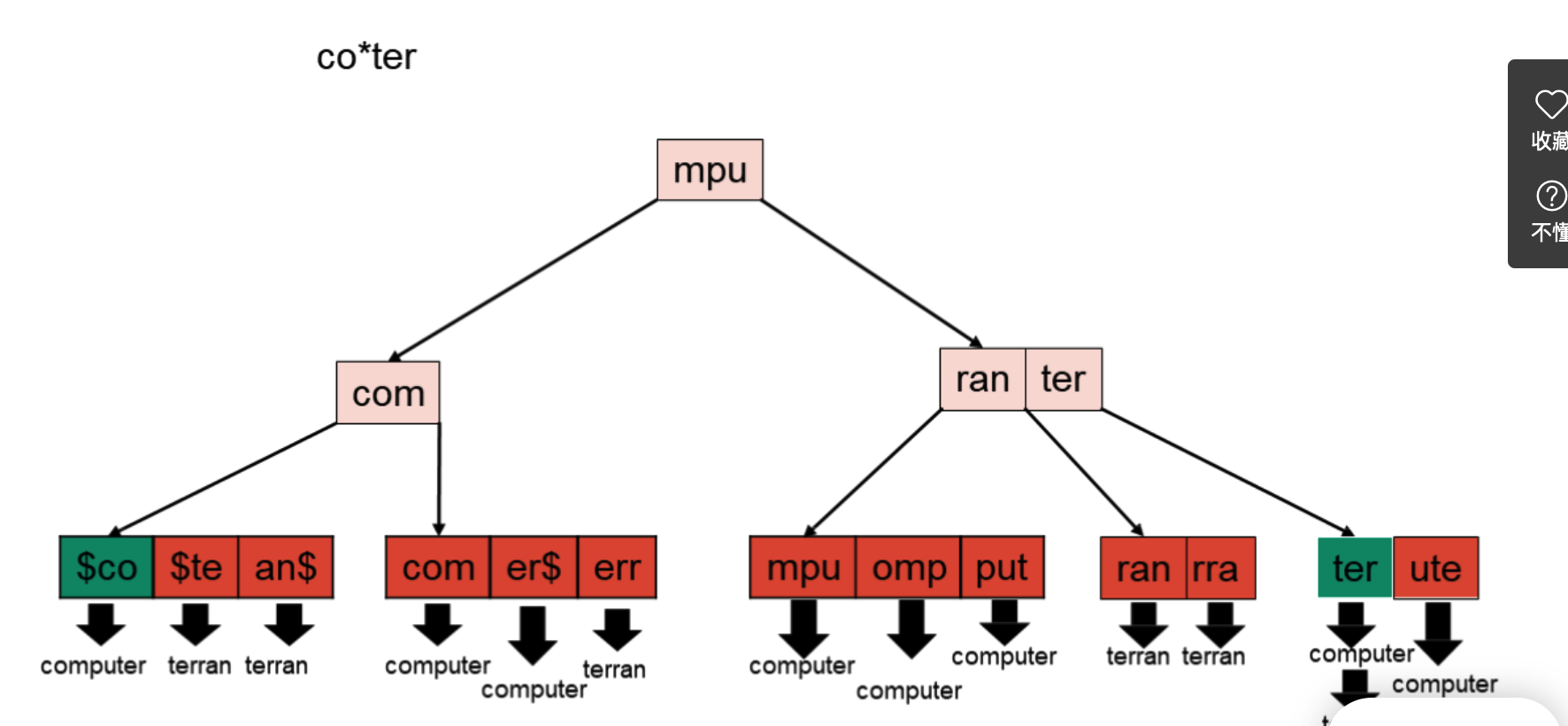
K-gram
一定程度上的优化
在一定长度的字串上建索引

查$co,ter,er$,$代表起始和结束符号
拼写检查支持
动态规划:编辑距离
动态规划求字符串距离?

词项太多,算法显得有些复杂,慢
在K-gram基础上进行
Jaccard distance判断相似度
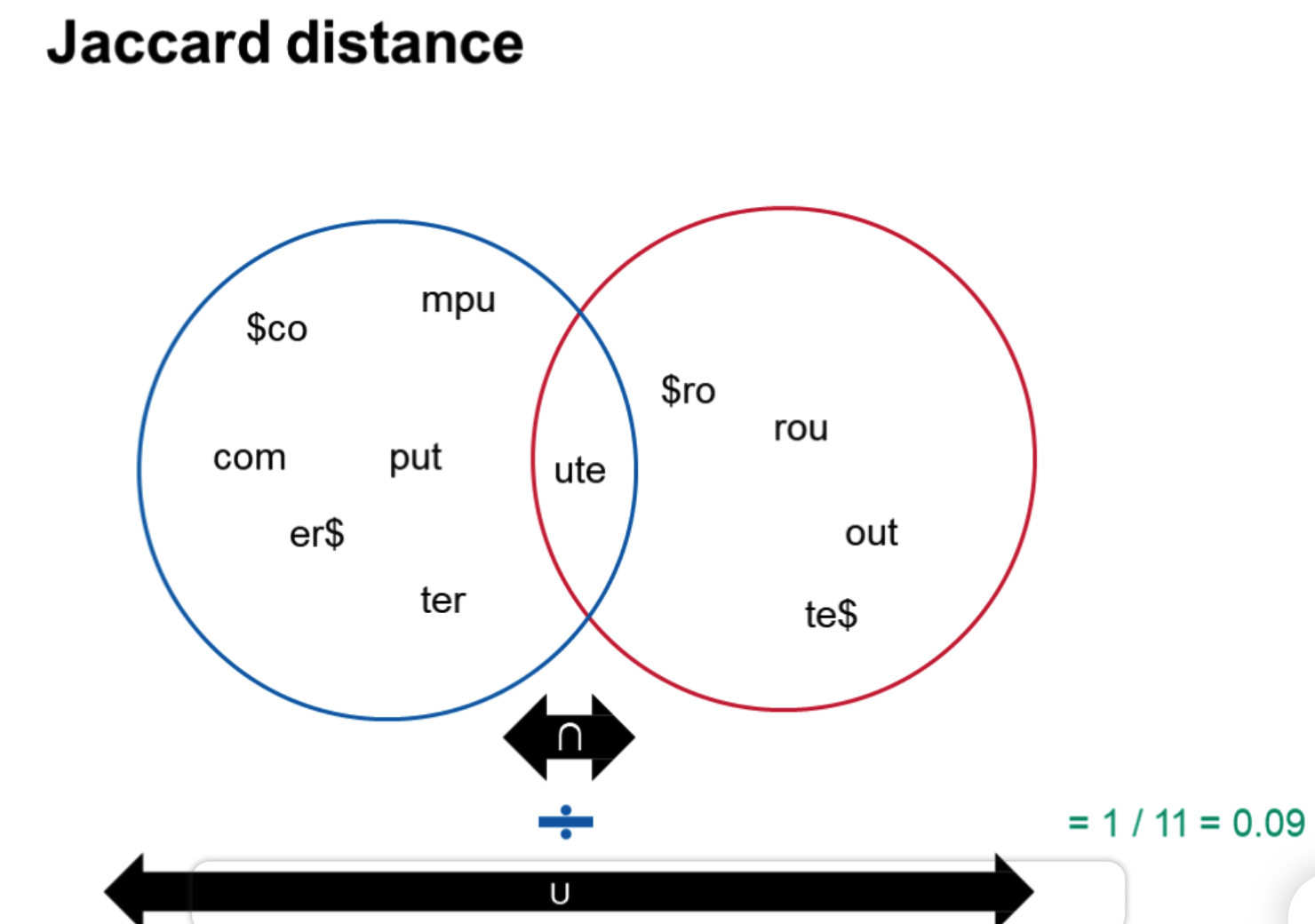
求并集的小trick
#query term's k-grams +#found term's k-grams-#intersection
上下文相关检查
利用搜索历史,启发式