南京大学ics2019_PA3
PA3实验报告
2013599 田佳业
一阶段
实现异常响应机制
对于x86,"上文提到的新指令“比较多,这里先按在nanos-lite中make ARCH=x86-nemu run报错的顺序来补充指令。
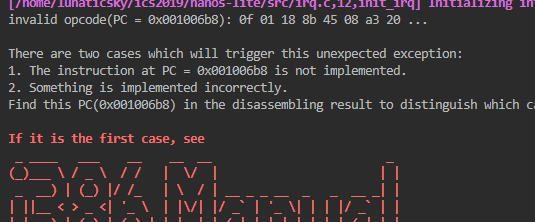
查看手册,这是Grp7中lidt指令。
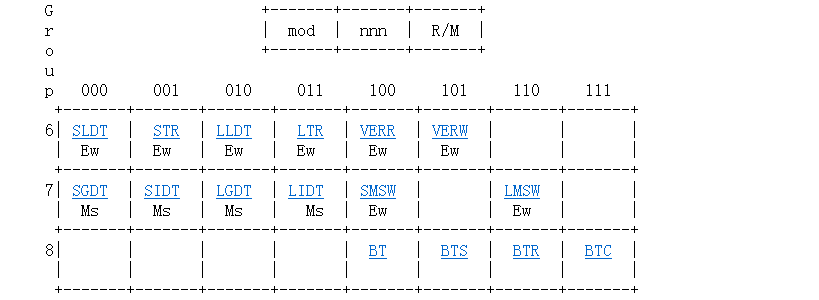
IDTR的格式在这,Figure9-1:
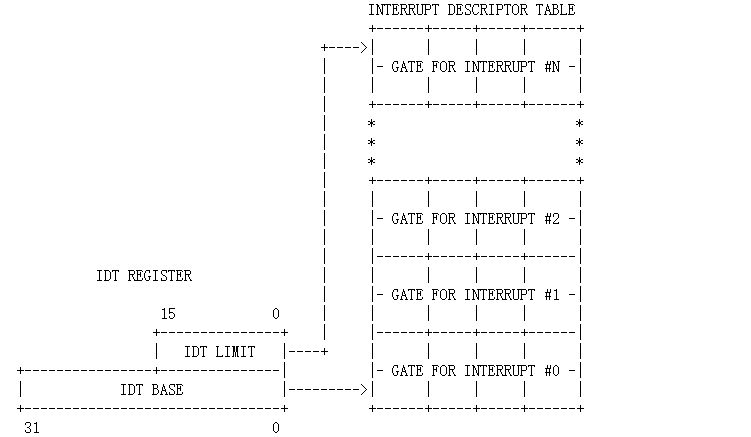
因此我们的寄存器结构应该长这样:
struct{
rtlreg_t limit : 16;
rtlreg_t base : 32;
} idtr;下面为其添加执行操作。我们可以在手册中查到对应的伪代码。因为我们用不到GDT(NEMU里没有分段机制),因此只看上面部分即可。而且我们是模拟32位机器,根据我们寄存器结构的实现,我们只需要实现ELSE部分即可。

综上,代码如下所示:
make_EHelper(lidt) {
//TODO();
rtl_li(&s0,id_dest->addr);
cpu.idtr.limit=vaddr_read(s0,2);
cpu.idtr.base=vaddr_read(s0+2,4);
print_asm_template1(lidt);
}注册新指令,跑一下:

嗯,该实现int指令了(之前注册过opcode_table,所以直接跳到这里了)
讲义中特意提及:
你需要在自陷指令的helper函数中调用
raise_intr(), 而不要把异常响应机制的代码放在自陷指令的helper函数中实现, 因为在后面我们会再次用到raise_intr()函数.
因此我们先看这个函数该怎么实现。代码里只有一对括号,但讲义告诉我们了触发中断的响应过程:
- 依次将eflags, cs(代码段寄存器), eip(也就是PC)寄存器的值压栈
- 从IDTR中读出IDT的首地址
- 根据异常号在IDT中进行索引, 找到一个门描述符
- 将门描述符中的offset域组合成异常入口地址
- 跳转到异常入口地址
为了diftest,我们需要手动添加cs寄存器,在寄存器结构体里补充一下即可。
下面是依据四个步骤实现的raise_intr。其中额外关中断防止嵌套中断,并检查了特权级(额外是指不这么做也不影响NEMU实现的正确)
void raise_intr(uint32_t NO, vaddr_t ret_addr)
{
/* TODO: Trigger an interrupt/exception with ``NO''.
* That is, use ``NO'' to index the IDT.
*/
// step1
rtl_push(&cpu.eflags.val);
rtl_push(&cpu.cs);
rtl_push(&ret_addr);
cpu.eflags.IF = 0;
// step2
uint32_t gate_addr = cpu.idtr.base, len = cpu.idtr.limit;
if (len <= NO)
{
printf("the number is larger than the length of IDT!\n");
assert(0);
}
//step3
uint32_t val_l, val_h, p;
val_l = vaddr_read(gate_addr + NO * 8, 2);
val_h = vaddr_read(gate_addr + NO * 8 + 6, 2);
p = vaddr_read(gate_addr + NO * 8 + 5, 1) >> 7;
//actually no need to check p for NEMU, but we can do it.
if (!p)
{
printf("The gatedesc is not allowed!");
assert(0);
}
//step4
//using rtl api
vaddr_t goal = (val_h << 16) + val_l;
rtl_j(goal);
}int指令根据手册有三种。0xcc的是断点,0xcd的是一般的中断指令,0xce是溢出中断指令。0xcc和0xce中断号分别为3和4。decinfo.seq_pc中保存的是int
指令的下一条指令。因此可以做以下实现:
make_EHelper(int) {
// TODO();
switch(decinfo.opcode){
case 0xcc : raise_intr(0x3,decinfo.seq_pc); break;
case 0xcd : raise_intr(id_dest->val, decinfo.seq_pc); break;
case 0xce : raise_intr(0x4, decinfo.seq_pc); break;
}
print_asm("int %s", id_dest->str);
difftest_skip_dut(1, 2);
}写完之后发现报错,是没有外部声明。在开头加上外部声明:
void raise_intr(uint32_t NO, vaddr_t ret_addr);关于讲义中提到阅读_cte_init()的代码,
找出相应的异常入口地址:对x86来说,
这个函数就是准备了一个有意义的IDT,出现异常的时候根据IDTR中保存的信息去找中断向量表即可。这个过程上面已经实现了。
然后是iret。这就是保存上下文部分的工作了,说明这一部分已经完成。
保存上下文
iret指令手册说的很复杂,但由于NEMU不涉及特权级和段机制,因此我们只需要关注一句话:
In Real Address Mode, IRET pops the instruction pointer, CS, and the flags register from the stack and resumes the interrupted routine.
故可实现如下:
make_EHelper(iret) {
//TODO();
rtl_pop(&s0);
rtl_j(s0);
rtl_pop(&cpu.cs);
rtl_pop(&cpu.eflags.val);
print_asm("iret");
}同raise_intr,恢复eip,更新decoding
中的跳转 eip
信息可以直接调用rtl_j实现。实际上就是跳到调用中断的地方去了。
pusha
顾名思义,它的功能是把所有通用寄存器都压入栈中。这个可以说是非常赏心悦目了,对照实现即可。popa显然也是对称的,不再赘述。
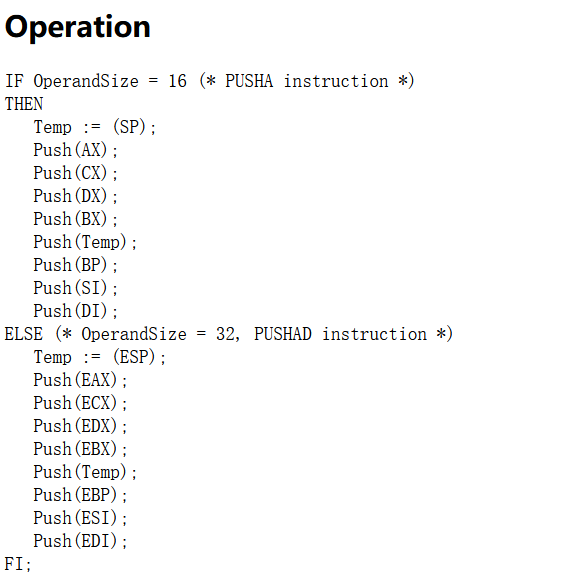
make_EHelper(pusha) {
//TODO();
rtl_mv(&s0,&cpu.esp);
rtl_push(&cpu.eax);
rtl_push(&cpu.ecx);
rtl_push(&cpu.edx);
rtl_push(&cpu.ebx);
rtl_push(&s0);
rtl_push(&cpu.ebp);
rtl_push(&cpu.esi);
rtl_push(&cpu.edi);
print_asm("pusha");
}接下来讲义要求我们重新组织Context结构体。这个地方卡了一段时间,确实如讲义所说,必须要理解整个中断调用过程,只看代码是看不出什么的。
触发异常后硬件处理第一步是通过raise_intr依次将触发异常时的PC和处理器状态(对于x86来说就是eflags,
cs和eip)压栈,根据异常号找到中断向量表中的中断描述符,描述符给出了该执行哪个中断。比如如果是80系统调用,程序运行后会触发trap.S汇编代码上面的第一个函数__am_vecsys,会压入异常号,然后跳转到__am_asm_trap()。在
__am_asm_trap()中,代码将会把用户进程的通用寄存器通过pusha保存到堆栈上。由此形成了陷阱帧。栈由改地址往低地址延伸,因此_Context的顺序与此相反,或者说和popa的顺序是一致的。
#----|------------entry------------|---irq id---|-----handler-----|
.globl __am_vecsys; __am_vecsys: pushl $0x80; jmp __am_asm_trap
......
__am_asm_trap:
pushal
pushl $0
pushl %esp
call __am_irq_handle事件分发
讲义中指出,这是因为CTE的__am_irq_handle()函数并未正确识别出自陷事件.
根据_yield()的定义,
__am_irq_handle()函数需要将自陷事件打包成编号为_EVENT_YIELD的事件。让它识别一下就好:
switch (c->irq) {
case 0x81:ev.event=_EVENT_YIELD;break;
default: ev.event = _EVENT_ERROR; break;
}do_event也识别一下:
switch (e.event) {
case _EVENT_YIELD: Log("_EVENT_YIELD recognized");break;
default: panic("Unhandled event ID = %d", e.event);
}可以看到识别出来了。

恢复上下文
恢复上下文需要完成popa操作。因为我在实现pusha的时候已经完成了,因此这里直接触发了panic,任务完成。
必答题
从Nanos-lite调用_yield()开始,
到从_yield()返回的期间, 这一趟旅程具体经历了什么?
1.nexus-am/am/src/x86/nemu/cte.c 中,_yield
函数中执行指令 int 0x81。
void _yield() {
asm volatile("int $0x81");
}2.nemu/src/isa/x86/exec/system.c
中,exec_int 函数为 nemu 对 int 指令的执行函数,其中调用了
raise_intr 函数,参数为 int 中断编号(此处为 0x81)以及当前的
PC 值。一般的中断走的是0xcd分支。
make_EHelper(int) {
// TODO();
switch(decinfo.opcode){
case 0xcc : raise_intr(0x3,decinfo.seq_pc); break;
case 0xcd : raise_intr(id_dest->val, decinfo.seq_pc); break;
case 0xce : raise_intr(0x4, decinfo.seq_pc); break;
}
print_asm("int %s", id_dest->str);
difftest_skip_dut(1, 2);
}3.nemu/src/isa/x86/intr.c 中,raise_intr
函数中读取中断描述符表
idt,根据传入的中断编号得到中断处理程序的入口地址(中断描述符表的初始化在_cte_init
函数中完成)。接下来就是讲义中的触发异常后硬件的响应过程,我们依次对寄存器
eflags ,cs,eip
进行压栈,根据IDT找到入口地址,最后将程序转移到中断处理程序入口地址处继续执行。当中断编号为
0x81 时,在nexus-am/am/src/x86/nemu/cte.c
中的_cte_init
函数中我们可以看到中断处理程序为__am_vectrap
函数(下面idt[0x81]这一行),因此raise_intr
最终的效果是将虚拟机内部运行的程序转移到了其中断服务程序处继续执行。nemu
完成了 int 指令的执行。
int _cte_init(_Context*(*handler)(_Event, _Context*)) {
static GateDesc idt[NR_IRQ];
// initialize IDT
for (unsigned int i = 0; i < NR_IRQ; i ++) {
idt[i] = GATE(STS_TG32, KSEL(SEG_KCODE), __am_vecnull, DPL_KERN);
}
// ----------------------- interrupts ----------------------------
idt[32] = GATE(STS_IG32, KSEL(SEG_KCODE), __am_irq0, DPL_KERN);
// ---------------------- system call ----------------------------
idt[0x80] = GATE(STS_TG32, KSEL(SEG_KCODE), __am_vecsys, DPL_USER);
idt[0x81] = GATE(STS_TG32, KSEL(SEG_KCODE), __am_vectrap, DPL_KERN);
set_idt(idt, sizeof(idt));
// register event handler
user_handler = handler;
return 0;
}4.__am_vectrap
位于nexus-am/am/src/x86/nemu/trap.S 中,将整数 0x81
入栈,跳转到__am_asm_trap
继续执行。进行一系列压栈操作后(压的其实就是_Context结构体这个参数,这回答了讲义中“__am_irq_handle()有一个上下文结构指针c这个上下文结构c是怎么来的”这个问题),转移到函数__am_irq_handle
处执行。
.globl __am_vectrap; __am_vectrap: pushl $0x81; jmp __am_asm_trap
__am_asm_trap:
pushal
pushl $0
pushl %esp
call __am_irq_handle
addl $4, %esp
addl $4, %esp
popal
addl $4, %esp
iret5.nexus-am/am/src/x86/nemu/cte.c
中,函数__am_irq_handle 根据栈(上下文)
中保存的中断号对事件进行打包,调用user_handler对事件进行处理。其中user_handler
在_cte_init 中进行了初始化,为do_event
函数。
_Context* __am_irq_handle(_Context *c) {
_Context *next = c;
if (user_handler) {
_Event ev = {0};
switch (c->irq) {
case 0x81:ev.event=_EVENT_YIELD;break;
default: ev.event = _EVENT_ERROR; break;
}
next = user_handler(ev, c);
if (next == NULL) {
next = c;
}
}
return next;
}user_handler
是怎么初始化的呢?具体是_cte_init 中
user_handler = handler;这一句,而这个参数handler是init_irq时调用时传给它的,这也回到了main函数为实现上下文做准备的阶段。
void init_irq(void) {
Log("Initializing interrupt/exception handler...");
_cte_init(do_event);
}6.nanos-lite/src/irq.c 中,do_event
函数对传入的时间进行解析,做出相应的操作,对于 yield
操作,我们现在直接输出一段文本,表示程序运行至此即可。顾名思义的话应该是要做进程调度,但我们现在仅有一个上下文,因此不做上下文切换,此处直接返回NULL
给__am_irq_handle。
static _Context* do_event(_Event e, _Context* c) {
switch (e.event) {
case _EVENT_YIELD: Log("_EVENT_YIELD recognized");break;
default: panic("Unhandled event ID = %d", e.event);
}
return NULL;
}7.接下来就是沿着上述调用链逐级返回的操作。__am_irq_handle
得到 do_event返回的
NULL后,不做上下文切换,直接将传入的上下文返回给调用者__am_asm_trap,
经过适当的出栈操作后,使用 iret
指令进行中断返回,回复现场,回到中断前程序的执行位置。至此,一次自陷操作全部完成。
__am_irq_handle:
if (next == NULL) {
next = c;
}
}
return next;trap.S
call __am_irq_handle
addl $4, %esp
addl $4, %esp
popal
addl $4, %esp
iretiret
make_EHelper(iret) {
rtl_pop(&s0);
rtl_j(s0);
rtl_pop(&cpu.cs);
rtl_pop(&cpu.eflags.val);
print_asm("iret");
}这个必答题按照整个触发中断时进行上下文管理的过程梳理了一遍。上述实现的过程中是发现缺什么需要补充的,看懂局部的过程进行补充,而在此对整个过程进行了整体的总结。
思考题
对比异常处理与函数调用
我们知道进行函数调用的时候也需要保存调用者的状态: 返回地址, 以及calling convention中需要调用者保存的寄存器. 而CTE在保存上下文的时候却要保存更多的信息. 尝试对比它们, 并思考两者保存信息不同是什么原因造成的。
综合上述提到的异常处理过程,对于x86多保存的主要有eflags ,cs,eip和通用寄存器。主要原因是调用子程序过程发生的时间是已知和固定的,即在主程序中的调用指令 (CALL)执行时发生,所以我们只需要保存子函数中需要的东西,以及保存返回地址,ebp确保能回到调用者那里就可以。而中断/异常发生的时间一般是随机的。意味着我们需要为当前的寄存器状态提供一个“快照”,因此几乎保存了所有的寄存器。
二阶段
实现loader
讲义中指出,现在的ramdisk十分简单, 它只有一个文件,
就是我们将要加载的用户程序dummy,可执行文件位于ramdisk偏移为0处,
访问它就可以得到用户程序的第一个字节.
关于用户程序需要加载到的内存位置
ics2019是这么说的:
为了避免和Nanos-lite的内容产生冲突, 我们约定目前用户程序需要被链接到内存位置
0x3000000(x86)或0x83000000(mips32或riscv32)附近, Navy-apps已经设置好了相应的选项(见navy-apps/Makefile.compile中的LDFLAGS变量).
ics2018
用户程序需要被链接到内存位置
0x4000000处
而且,ics2018这个是作为第一个热身任务,是这么说的:
loader 只需要做一件事情:将 ramdisk 中从 0 开始的所有内容放置在 0x4000000,并把这个地 址作为程序的入口返回即可。
但ics2019这个地方就有些复杂,这个地方也研究了好半天。其中这篇博客造了一个轮子,但也让我清楚了到底想让我们干什么。
程序开始的地方由ELF header中的Entry point
address来指示,因此我们读出来,返回这个入口地址就可以了。下面的naive_uload
将程序入口强制转换一个函数指针并调用,因此我们确信就直接返回这个地址值就可以了。
void naive_uload(PCB *pcb, const char *filename) {
uintptr_t entry = loader(pcb, filename);
Log("Jump to entry = %p", entry);
((void(*)())entry) ();
}但是讲义里还提到:
你需要找出每一个需要加载的segment的
Offset,VirtAddr,FileSiz和MemSiz这些参数. 其中相对文件偏移Offset指出相应segment的内容从ELF文件的第Offset字节开始, 在文件中的大小为FileSiz, 它需要被分配到以VirtAddr为首地址的虚拟内存位置, 在内存中它占用大小为MemSiz. 也就是说, 这个segment使用的内存就是[VirtAddr, VirtAddr + MemSiz)这一连续区间, 然后将segment的内容从ELF文件中读入到这一内存区间, 并将[VirtAddr + FileSiz, VirtAddr + MemSiz)对应的物理区间清零。
因此还没完。我们没有做清零的工作。因此我们还要根据ELF header知道有几个segments,然后从Program Header中知道segment的属性。讲义中有一个图表现的比较清楚。然后对每一个段清零。代码如下所示:
static uintptr_t loader(PCB *pcb, const char *filename) {
// TODO();
Elf_Ehdr elf_header;
size_t offset=ramdisk_read(&elf_header,0,sizeof(Elf_Ehdr));
assert(offset==sizeof(Elf_Ehdr));
Elf_Phdr elf_program_header[elf_header.e_phnum];
offset=ramdisk_read(elf_program_header,elf_header.e_phoff,sizeof(Elf_Phdr)*elf_header.e_phnum);
assert(offset==sizeof(Elf_Phdr)*elf_header.e_phnum);
for(int i=0;i<elf_header.e_phnum;i++){
// only load PT_LOAD type
if(elf_program_header[i].p_type==PT_LOAD){
ramdisk_read((void*)elf_program_header[i].p_vaddr,elf_program_header[i].p_offset,elf_program_header[i].p_memsz);
// clear the [Virtual Address + File Size, Virtual Address + Memory Size)
memset((void*)(elf_program_header[i].p_vaddr+elf_program_header[i].p_filesz),0,elf_program_header[i].p_memsz-elf_program_header[i].p_filesz);
}
}
return elf_header.e_entry;
}实现完了按照提示在init_proc()中调用naive_uload(NULL, NULL)。需要在上面声明一下:
void init_proc() {
switch_boot_pcb();
Log("Initializing processes...");
// load program here
naive_uload(NULL, NULL);
}但是为什么报错呢?使用objdump -S dummy-x86 >dump.txt查看dummy的反汇编代码,发现入口确实找对了,还是这个endbr32的
鬼。这好说,改一改编译选项的事,PA2已经遇到过了。
加到navy_apps的Makefile.compile里面就好。

同理,在navy_apps底下也要make clean才能生效。
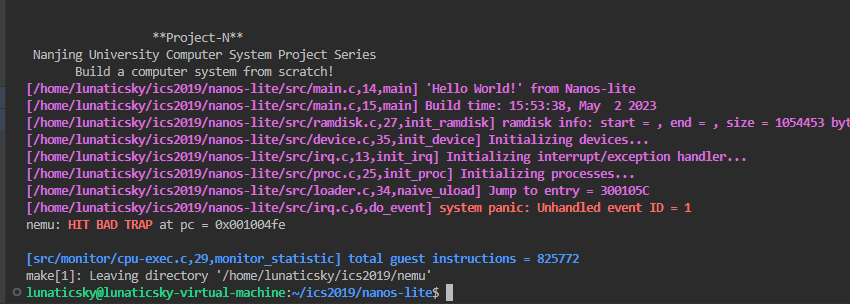
说明loader已经成功加载dummy。
堆和栈在哪里
栈的使用只发生在函数调用过程中,堆的使用只发生在malloc/free函数调用之后,因此它们都只在动态时有意义,这是为什么它们不需要出现在可执行文件中。
如何识别不同格式的可执行文件?
如果你在GNU/Linux下执行一个从Windows拷过来的可执行文件, 将会报告"格式错误". 思考一下, GNU/Linux是如何知道"格式错误"的?
根据ELF 文件头的前 4 个字节即“魔数”判断。
为什么要清零?
为什么需要将 [VirtAddr + FileSiz, VirtAddr + MemSiz)
对应的物理区间清零?
如讲义中所说,FileSiz 表示这个段在文件中的大小,而 MemSiz 表示这个段在内存中的大小。我们知道可执行文件的各个段包括代码段、数据段、BSS 段等。由于 BSS 段没有实际的数据,所以它的 FileSiz 为 0,而 MemSiz 表示它需要占用的空间大小。BSS 段是程序运行时未初始化的全局变量和静态变量所占据的内存空间,我们写C程序知道这变量默认应当为0的,因此要清零。
识别系统调用
a[0] = c->GPR1;保存的是系统调用的参数,dummy程序,
它触发了一个SYS_yield系统调用. 我们约定,
这个系统调用直接调用CTE的_yield()即可,
然后返回0.因此我们需要处理的第一个case是SYS_yield。下面又说“处理系统调用的最后一件事就是设置系统调用的返回值.
对于不同的ISA, 系统调用的返回值存放在不同的寄存器中,
宏GPRx用于实现这一抽象,
所以我们通过GPRx来进行设置系统调用返回值即可.”换句话说,刚才的返回0就是把这个GPRx寄存器设置成0;查看宏定义,它在x86中是eip。这不是胡扯吗。。eip是指针寄存器,返回值应当存到通用寄存器里啊。看要求果然有“在nexus-am/am/include/arch/$ISA-nemu.h中实现正确的GPR?宏”,因此我们先把这个错改过来:
#define GPR1 eax
#define GPR2 ebx
#define GPR3 ecx
#define GPR4 edx
#define GPRx eax依据的是下面的定义:
// ISA-depedent definitions
#if defined(__ISA_X86__)
# define ARGS_ARRAY ("int $0x80", "eax", "ebx", "ecx", "edx", "eax")这个ARRAY对应的就是封装的系统调用的四个参数:
intptr_t _syscall_(intptr_t type, intptr_t a0, intptr_t a1, intptr_t a2) {
register intptr_t _gpr1 asm (GPR1) = type;
register intptr_t _gpr2 asm (GPR2) = a0;
register intptr_t _gpr3 asm (GPR3) = a1;
register intptr_t _gpr4 asm (GPR4) = a2;
register intptr_t ret asm (GPRx);
asm volatile (SYSCALL : "=r" (ret) : "r"(_gpr1), "r"(_gpr2), "r"(_gpr3), "r"(_gpr4));
return ret;
}然后我们去按部就班实现“约定”:
switch (a[0]) {
case SYS_yield: _yield(); c->GPRx = 0; break;
default: panic("Unhandled syscall ID = %d", a[0]);
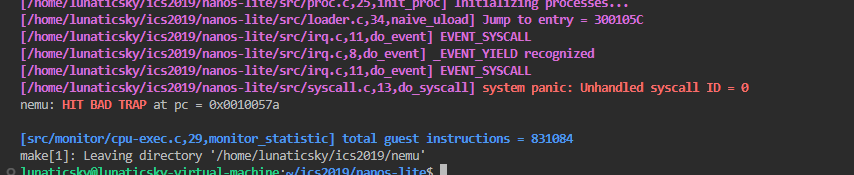
}do_event分发:
case _EVENT_SYSCALL:
Log("EVENT_SYSCALL");
do_syscall(c);发现还是不行。因为做完上下文管理和做这一部分中间隔了一段时间写qt大作业,所以不太熟悉了。仔细回顾了这一部分发现是没有在am中处理中断指令:
switch (c->irq)
{
case 0x80:
ev.event = _EVENT_SYSCALL;
break;
case 0x81:
ev.event = _EVENT_YIELD;
break;
default:
ev.event = _EVENT_ERROR;
break;
}
这次对了。0号事件好说。按照提示直接调用_halt
case SYS_exit: _halt(a[1]); break;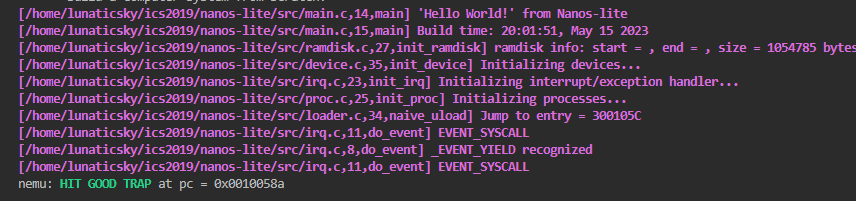
操作系统之上的TRM
标准输出
根据write的函数声明(不用man,代码里也可以看出来)
int _write(int fd, void *buf, size_t count) {
return _syscall_(SYS_write, fd, (intptr_t)buf, count);
}在do_syscall()中识别出系统调用号是SYS_write之后,
检查fd的值,
如果fd是1或2(分别代表stdout和stderr),
则将buf为首地址的len字节输出到串口(使用_putc()即可).
最后还要设置正确的返回值,
这一步就要man一下看看了。返回值的含义:

因此可做如下实现(do_syscall中):
case SYS_write:
{
int fd = (int)a[1];
char *buf = (char *)a[2];
size_t len = (size_t)a[3];
if(fd==1||fd==2){
for(int i=0;i<len;++i,++buf)
_putc(*buf);
c->GPRx=len;
}
else{
c->GPRx=-1;
}
break;
}不要忘了加break。。。。
好了,我们成功运行了永不停息的hello world。
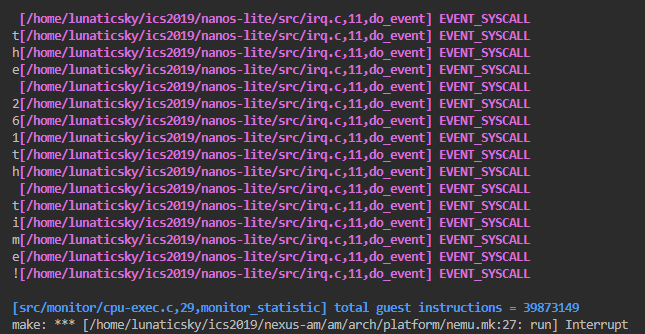
堆区管理
_sbrk()实现:
- program break一开始的位置位于
_end - 被调用时, 根据记录的program break位置和参数
increment, 计算出新program break - 通过
SYS_brk系统调用来让操作系统设置新program break - 若
SYS_brk系统调用成功, 该系统调用会返回0, 此时更新之前记录的program break的位置, 并将旧program break的位置作为_sbrk()的返回值返回 - 若该系统调用失败,
_sbrk()会返回-1
extern char _end;
...
static intptr_t program_break=(intptr_t)&_end;
void *_sbrk(intptr_t increment) {
intptr_t prev_break=program_break;
if(_syscall_(SYS_brk,program_break+increment,0,0)==0){
program_break+=increment;
return (void *)prev_break;
}
else{
return (void *)-1;
}
}暂时只有单道应用程序,认为堆区分配总能成功:
case SYS_brk:
c->GPRx = 0;
break;输出能够走缓冲区了:
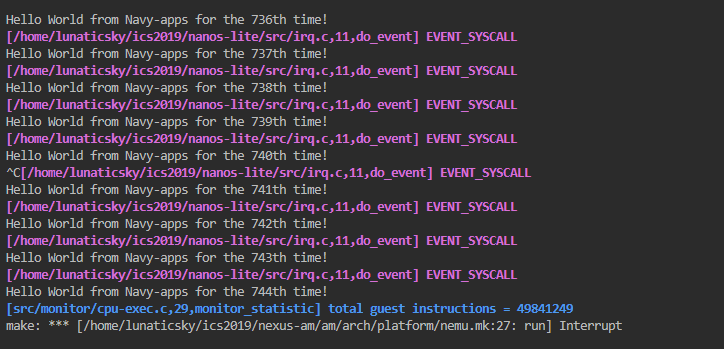
必答题
hello程序是什么,
它从而何来, 要到哪里去,它能吃吗
三阶段
让loader使用文件
实验指导书中说,需要先实现fs_open(),
fs_read()和fs_close(),
这样就可以在loader中使用文件名来指定加载的程序了。但是按照指导书的指示先实现了这三个指令,仿照原来的loader把所有的randisk_read改成fs_read后却一直内存超限。一想,fs_read只能从当前的open_offset开始读啊,读pheader时我们要从elf_header.e_phoff开始读。后面读每个块的时候也是类似。所以fs_lseek还是必不可少。当时实现loader的细节有些模糊了,所以干了蠢事。
Elf_Ehdr elf_header;
int fd = fs_open(filename,0,0);
Log("filename: %s, fd: %d", filename, fd);
size_t read_len = fs_read(fd, &elf_header, sizeof(Elf_Ehdr));
assert(read_len == sizeof(Elf_Ehdr));
Elf_Phdr elf_program_header[elf_header.e_phnum];
fs_lseek(fd, elf_header.e_phoff, SEEK_SET);
read_len = fs_read(fd, elf_program_header, sizeof(Elf_Phdr) * elf_header.e_phnum);
assert(read_len == sizeof(Elf_Phdr) * elf_header.e_phnum);
for (int i = 0; i < elf_header.e_phnum; i++)
{
// only load PT_LOAD type
if (elf_program_header[i].p_type == PT_LOAD)
{
fs_lseek(fd, elf_program_header[i].p_offset, SEEK_SET);
read_len=fs_read(fd, (void *)elf_program_header[i].p_vaddr, elf_program_header[i].p_memsz);
assert(read_len==elf_program_header[i].p_memsz);
memset((void *)(elf_program_header[i].p_vaddr + elf_program_header[i].p_filesz), 0, elf_program_header[i].p_memsz - elf_program_header[i].p_filesz);
}
}
fs_close(fd);
return elf_header.e_entry;另外,关于如何加载新的文件也找了一些时间,在这里:
void init_proc() {
switch_boot_pcb();
Log("Initializing processes...");
char filename[] = "/bin/events";
// load program here
naive_uload(NULL, filename);
}实现完整的文件系统
另外几个api的实现较为简单(虽然中间fs_write还是写错了一次),类似于PA2中的scanf等实现,按照其原本的含义man一下对照实现即可。代码不再赘述。
最后,还要注册事件,还有要在navy-apps/libs/libos/src/nanos.c里调用系统调用接口,当时实现sbrk的时候说了,文件系统没有说,就忘了,还一直疑惑明明实现的没问题就是打不开文件。。。
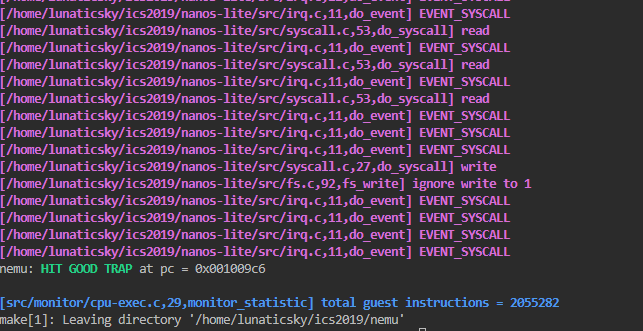
单元测试成功:
操作系统之上的IOE
串口
size_t serial_write(const void *buf, size_t offset, size_t len) {
// return 0;
for (int i = 0; i < len; i++)
{
_putc(((char *)buf)[i]);
}
return len;
}这时候读写文件就不需要对标准输入输出特判了,如:
if (fd <= 2)
{
Log("ignore read from %d", fd);
return 0;
}设备
size_t events_read(void *buf, size_t offset, size_t len)
{
// return 0;
int key = read_key();
if (key != _KEY_NONE) // key event
{
// Log("key event");
if (key & 0x8000)
{
// if (key>=0x8002&&key<=0x8004) change_gcb(key-0x8001);
sprintf((char *)buf, "kd %s\n", keyname[key & 0x7fff]);
}
else
{
sprintf((char *)buf, "ku %s\n", keyname[key & 0x7fff]);
}
}
else // time event
{
// if (now%1000==0) Log("time event");
sprintf((char *)buf, "t %d\n", uptime());
}
return strlen((char *)buf);
}这一部分一开始直接把函数参数里的len给返回了,就会一直报receive event。
更新文件描述表:
static Finfo file_table[] __attribute__((used)) = {
{"stdin", 0, 0, invalid_read, invalid_write},
{"stdout", 0, 0, 0, invalid_read, serial_write},
{"stderr", 0, 0, 0, invalid_read, serial_write},
{"/dev/events", 0, 0, 0, events_read, invalid_write},
#include "files.h"
};正常工作:
VGA
这一部分指导书上说的是非常贴心,每一步该干什么都非常明确,真是非常难得。
其中主要是fb_write需要额外思索一下,其他的都是比较常规的流程。
另外注意VGA的一个像素占4bit。
size_t fb_write(const void *buf, size_t offset, size_t len)
{
int width=screen_width();
int x=(offset/4)%width,y=(offset/4)/width;
draw_rect((uint32_t*)buf,x,y,len/4,1);
return len;
}这一步也遇到了跑不起来的问题,不过补充了缺少的指令也成功运行起来了:
运行仙剑奇侠传
上一个vga实现movsb,紧接着实现movswd,将编译好的pal放到对应文件夹中,就可以运行了。


展示批处理系统
这是ics2019新加的一部分,实现起来非常简单,就是按照系统调用的逻辑,退出一个程序后把这个菜单程序再load进来。虽然简单,但是足够体现“操作系统的目的就是为了支持多道程序运行”的含义了。来看看我们现在都能支持哪些程序运行了。


必答题
仙剑奇侠传究竟如何运行
读出仙鹤信息
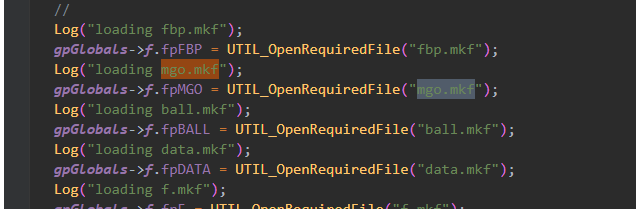
可以看到打开mgo.mkf调用了库函数fopen
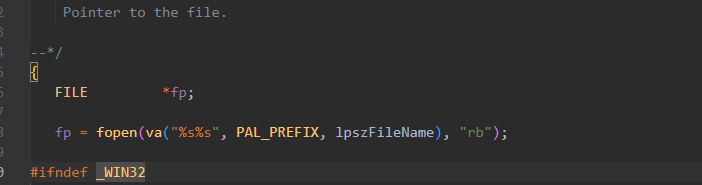
播放暂停时还会调用
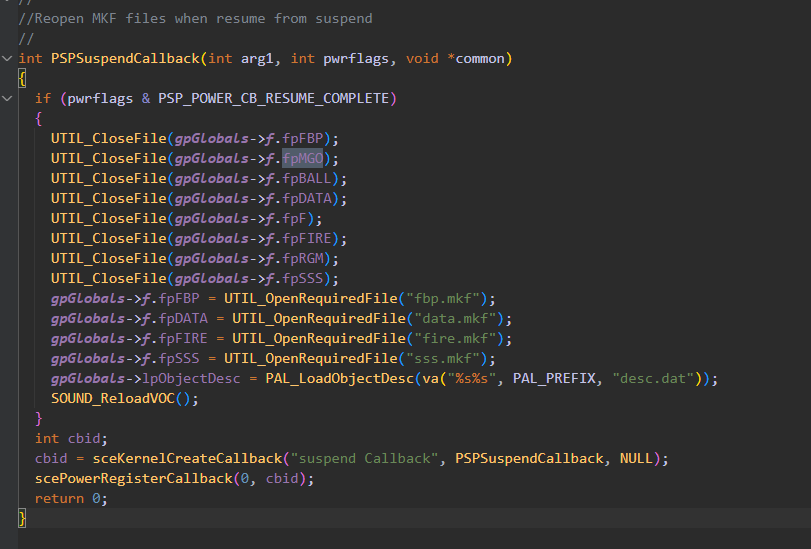
也是直接调用库函数。
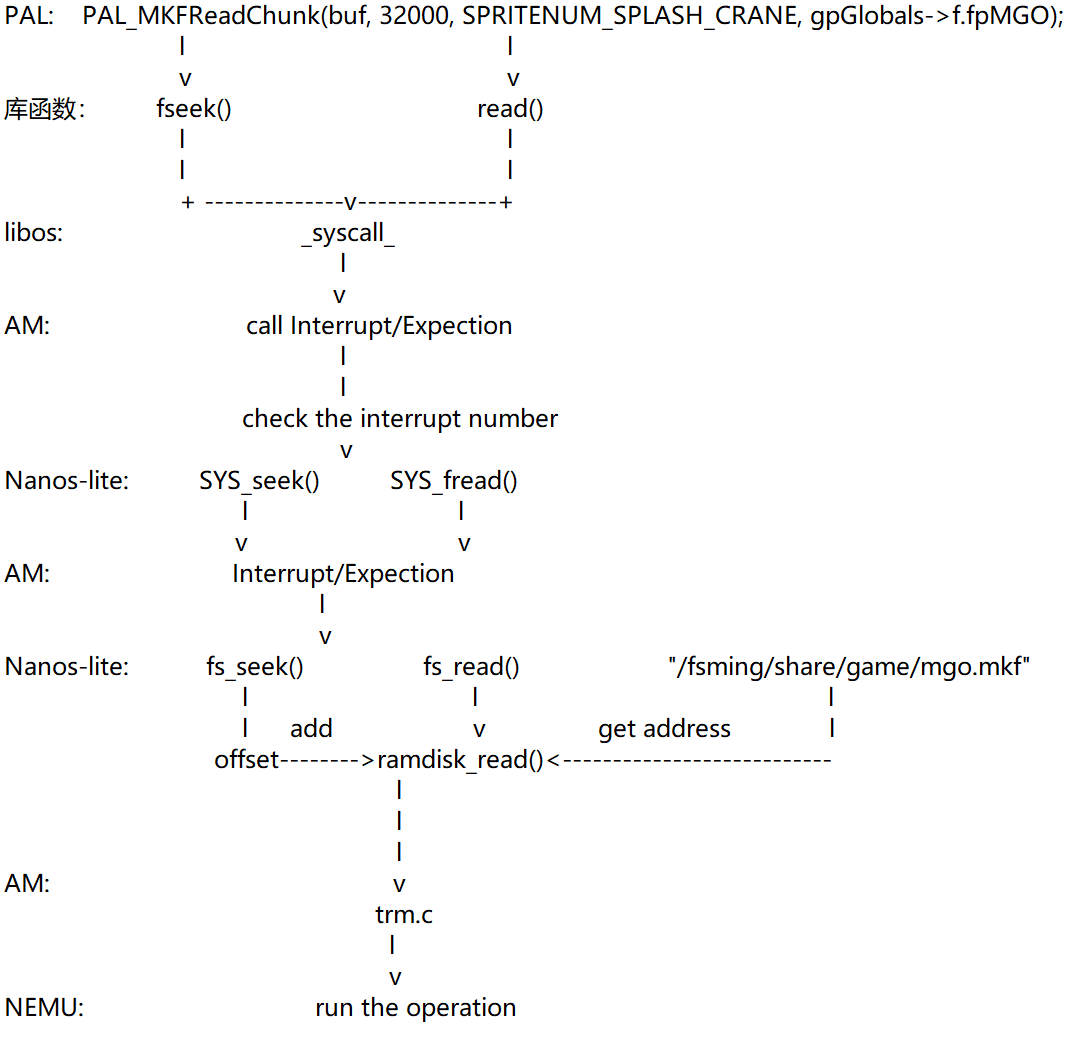
这一部分的过程网上有一张图画的非常清晰,就不班门弄斧了:
更新位置
这一部分如指导书所说,主要是PAL_SplashScreen()完成的。
首先Allocate all the needed memory at once for simplification,调用的是库中的calloc。
然后初始化屏幕
VIDEO_CreateCompatibleSurface -> VIDEO_CreateCompatibleSizedSurface -> SDL_CreateRGBSurface
读图片,获取仙鹤位置。这一部分前面已经分析了。
播放背景音乐。目前还没实现。
响应键盘事件,画屏幕
- 背景:VIDEO_CopySurface -> SDL_BlitSurface
- 仙鹤 & 标题:一些特殊的方法,最后都归结为更新像素信息
- VIDEO_UpdateScreen -> (SDL_SoftStretch) / SDL_FillRect / SDL_UpdateRect
- SDL_UpdateRect -> NDL_DrawRect -> open and write
/dev/fb
最后通过PAL_ProcessEvent触发系统调用。这就是前面必答题中的内容了。