南京大学ics2019_PA4
PA4实验报告
2013599 田佳业
阶段一
实现上下文切换
- CTE的
_kcontext()函数
已经做了3个PA了,对“你需要“这样的字眼已经很敏感了.根据讲义:
在
kstack的底部创建一个以entry为返回地址的上下文结构(目前你可以先忽略arg参数), 然后返回这一结构的指针. Nanos-lite会调用_kcontext()来创建上下文, 并把返回的指针记录到PCB的cp中.
_Context *_kcontext(_Area stack, void (*entry)(void *), void *arg) {
_Context *new_p=(_Context*)(stack.end-sizeof(_Context));
new_p->eip=(uintptr_t)entry;
new_p->eflags=0x2;
new_p->cs=8;
return new_p;
}- Nanos-lite的
schedule()函数
如指导书所述
_Context *schedule(_Context *prev)
{
// save the context pointer
current->cp = prev;
// always select pcb[0] as the new process
current = &pcb[0];
// then return the new context
return current->cp;
}- 在Nanos-lite收到
_EVENT_YIELD事件后, 调用schedule()并返回新的上下文
nanos-lite/src/irq.c
case _EVENT_YIELD:
Log("_EVENT_YIELD recognized");
return schedule(c);- 修改CTE中
__am_asm_trap()的实现, 使得从__am_irq_handle()返回后, 先将栈顶指针切换到新进程的上下文结构, 然后才恢复上下文, 从而完成上下文切换的本质操作
这一部分是最核心的。
nexus-am/am/src/x86/nemu/trap.S
__am_asm_trap:
pushal
pushl $0
pushl %esp
call __am_irq_handle
addl $4, %esp
movl %eax,%esp
addl $4, %esp
popal
addl $4, %esp
iret加的是movl %eax,%esp。为什么呢?__am_irq_handle在cte.c中返回的正是_Context结构体的指针,保存在eax寄存器中。原来的时候我们直接跳过这个返回值,恢复中断调用前的上下文。现在我们将栈顶指针指到这个上下文地址,我们后面就可以继续pop新的上下文信息,从而实现乾坤挪移。
另外这样之后movl %eax,%esp前面那句其实也并不起什么作用了。原来的目的是跳过压栈的esp,现在move指令既然都能直接跳转到另外一个进程的_Context结构体的位置了(虽然也有可能还是自身),减不减已经无所谓了。
最后进行测试:
void init_proc()
{
context_kload(&pcb[0], hello_fun);
switch_boot_pcb();
Log("Initializing processes...");
// char filename[] = "/bin/init";
// // load program here
// naive_uload(NULL, filename);
}注意按照指导书,我们就不需要使用原来的naive_uload()了。context_kload会调用CTE的kcontext()来创建一个上下文。调用switch_boot_pcb()则是为了初始化current指针.
实现上下文切换(2)
- 修改CTE的
_kcontext()函数, 使其支持参数arg的传递
这个地方就涉及到x86的函数调用约定了。讲义中提到“mips32和riscv32的调用约定”需要查阅相应的ABI手册,默认我们知道x86的调用约定(捂脸)。借此问题也回顾模拟了PA3中中断调用的过程。感谢某舍友的帮助,非常有耐心的让我把模糊的细节弄清楚了。详细见必答题部分。
现在增加了参数,就不再是这样了。因此原来的
_Context *new_p=(_Context*)(stack.end-sizeof(_Context));现在还要多减一些,因为end不再紧跟context了,而是依次多了返回值和函数参数。
当然我们还要把参数放到正确的位置。显然这个位置是(stack.end-4,stack.end],按照函数调用约定。距离上下文结构体(切换的栈帧底部)需要留出返回地址所在的4字节位置。
原来这个函数是没有arg参数的,现在我们需要手动加上。参数所指向的地址(4字节)。
_Context *_kcontext(_Area stack, void (*entry)(void *), void *arg) {
_Context *new_p=(_Context*)(stack.end-sizeof(_Context)-8);
void ** temp=(void**)(stack.end-4);
*temp=arg;
new_p->eip=(uintptr_t)entry;
new_p->eflags=0x2;
new_p->cs=8;
return new_p;
}根据上面的解释为什么减8也比较清楚了,还是需要注意arg是个指针,不管它的内容具体是多少都是占4字节。
- 修改
hello_fun()函数, 使其输出参数. 你可以自行约定参数arg的类型, 包括整数, 字符, 字符串, 指针等皆可, 然后按照你的约定来解析arg.
void hello_fun(void *arg)
{
int j = 1;
while (1)
{
// Log("Hello World from Nanos-lite for the %dth time!", j);
printf("%x",arg);
j++;
_yield();
}
}- 通过
_kcontext()创建第二个以hello_fun()为入口的内核线程, 并传递不同的参数
void init_proc()
{
context_kload(&pcb[0], hello_fun,1);
context_kload(&pcb[1], hello_fun,2);
switch_boot_pcb();
Log("Initializing processes...");
}- 修改Nanos-lite的
schedule()函数, 使其轮流返回两个上下文
_Context *schedule(_Context *prev)
{
// save the context pointer
current->cp = prev;
current = ((current == &pcb[0]) ? &pcb[1] : &pcb[0]);
// then return the new context
return current->cp;
}
实现多道程序系统
_Context *_ucontext(_AddressSpace *as, _Area ustack, _Area kstack, void *entry, void *args) {
_Context *new_p=(_Context*)(ustack.end-16-sizeof(_Context));
new_p->eip=(uintptr_t)entry;
new_p->cs=8;
new_p->eflags=0x00000202;
new_p->as=as;
return new_p;
}为什么减16呢?同样的道理,讲义中提到:
操作系统在加载用户进程的时候, 还需要负责把
argc/argv/envp以及相应的字符串放在用户栈中, 并把它们的存放方式和位置作为和用户进程的约定之一, 这样用户进程在_start中就可以访问它们了.
argc/argv/envp加上返回地址,就是4个4字节的指针,按照调用约定放到栈底。不过这个是在讲义后面提到的,也是阅读了这一部分才明白原理。
形象点说就是这样: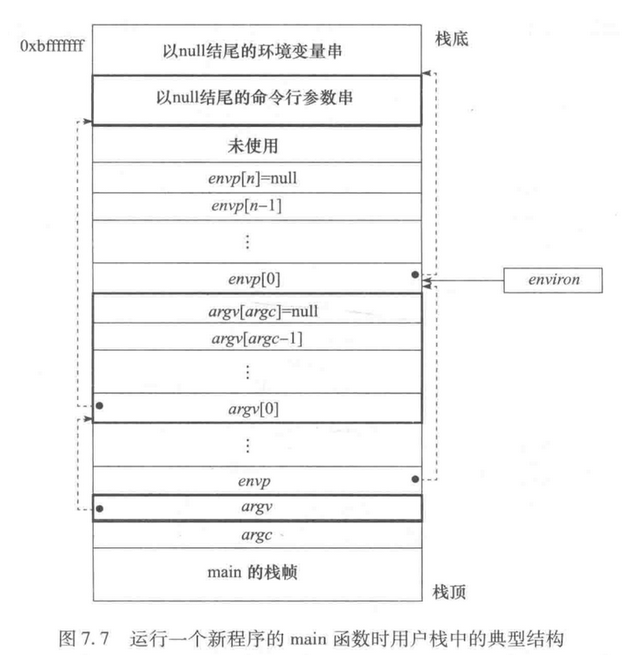
图来自于袁老师《计算机系统基础》课本第七章
还ics2021讲义里面是有这个图的,2019就没有,可能也是因为很多外校学生做实验的时候不知道这事(捂脸)
至于讲义中
需要在
serial_write(),events_read()和fb_write()的开头调用_yield(), 来模拟设备访问缓慢的情况. 添加之后, 访问设备时就要进行上下文切换, 从而实现多道程序系统的功能.
并不是完成这个任务所必须的,只是为了更符合“实际情况”。
context_kload(&pcb[1], hello_fun,2);
context_uload(&pcb[0], "/bin/pal");注意至少得有一个内核进程。一开始我写成了这样:
context_uload(&pcb[0], "/bin/hello");
context_uload(&pcb[1], "/bin/pal");内核便会不断的重启。
读到后面发现这就是讲义中的一山不能藏二虎?问题。
解答:编译Navy-apps中的程序时, 我们都把它们链接到0x83000000的内存位置, 如果我们正在运行仙剑奇侠传, 同时也想运行hello程序, 它们的内容就会被相互覆盖。
给用户进程传递参数
这一部分耗费的时间大概几乎是其他所有部分的总和(捂脸),但是做完所有实验还是没有解决这个问题。
这一部分讲义就讲的和实际不一致。
根据这一约定, 你还需要修改Navy-apps中
_start的代码, 在其调用call_main()之前把它的参数设置成argc的地址. 然后修改navy-apps/libs/libc/src/plaform/crt0.c中call_main()的代码, 让它解析出真正的argc/argv/envp, 并调用main(). 这样以后, 用户进程就可以接收到属于它的参数了.
Navy-apps中根本就没有_start函数,也没有什么call_main。但是call_main应当是指的crt_0中这个部分:
void _start(int argc, char *argv[], char *envp[]) {
char *env[] = {NULL};
environ = env;
printf("argc:%d\n",argc);
for(int i=0;i<argc;i++){
char *str=(char**)(argv[i]);
printf("argv[%d]:%s\n",i,str);
}
exit(main(argc, argv, env));
assert(0);
}正常的想法应该是这样,按照函数调用约定把字符数组首地址放到正确的位置:
_Context *new_p = (_Context *)(ustack.end - 16 - sizeof(_Context));
uintptr_t pos = ustack.end - 8;
void **argv_temp = (void **)(pos);
*argv_temp = (void *)(argv);
void **argc_temp = (void **)(ustack.end - 12);
*argc_temp = (void *)(argc);
// correct
// char* first_str=argv[0];
// printf("%s\n",first_str);
char *first_str = ((char **)(*argv_temp))[0];
printf("%s\n", first_str);
new_p->eip = (uintptr_t)entry;
new_p->cs = 8;
new_p->eflags = 0x00000202;
new_p->esp = (uintptr_t)(&new_p->irq);
new_p->as = as;
return new_p;
}但是这样argc没问题,argv却无法正常读取。和其他做2019的同学交流得知他们这样做是没有问题的。
甚至后面尝试了直接在栈上吧字符串数组放进去,当然虽然指导书是这么说的,但常量字符串应当在堆区,显然也是有些荒谬的。
int space_count=0;
if(argv){
for(int i=0;i<argc;i++){
space_count+=(strlen(argv[i])+1);
}
}
space_count+=argc;
space_count+=4; //return address,argc,argv,envp
space_count*=4; //4 bytes for each
printf("space_count:%d\n",space_count);
printf("end of stack addr:%x\n",ustack.end);
_Context *new_p=(_Context*)(ustack.end-space_count-sizeof(_Context));
void** argc_stack=(void**)(ustack.end-space_count+4);
*argc_stack=(void*)(argc);
// printf("argc:%d\n",(int)(*argc_stack));
//ignore the envp
// the pos to store strings
uintptr_t pos=ustack.end-space_count+16+argc*sizeof(char*);
printf("string storeing start addr:%x\n",pos);
char* argv_strs[argc];
uintptr_t argv_stack_addr=ustack.end-space_count+8;
void** argv_stack=(void**)(argv_stack_addr);
*argv_stack=(void*)(ustack.end-space_count+16);
printf("argv_stack addr:%x\n",(uintptr_t)(argv_stack));
printf("argv_stack value:%x\n",(uintptr_t)(*argv_stack));
extern memcpy(void* dst,void* src,size_t n);
for(int i=0;i<argc;i++){
void** str_stack=(void**)(pos);
//copy the string
// memcpy(*str_stack,argv[i],strlen(argv[i])+1);
strcpy(*str_stack,argv[i]);
printf("str %s stored at addr:%x\n",(char*)(*str_stack),(uintptr_t)(str_stack));
printf("the val of the str addr is %x\n",(uintptr_t)(*str_stack));
argv_strs[i]=(char*)(*str_stack);
pos+=strlen(argv[i])+1;
}
//copy the argv
// memcpy(*argv_stack,argv_strs,argc*sizeof(char*));
strcpy(*argv_stack,argv_strs);
for(int i=0;i<argc;i++){
void ** temp=(void**)(*argv_stack);
printf("argv %x stored at addr:%x\n",(uintptr_t)(temp[i]),(uintptr_t)(temp+i));
printf("it points to %s\n",(char*)(temp[i]));
}而且这种方法在开启分页之后也没跑成功。
后来发现有个博客的问题和我类似:
但是我尝试了传完整路径,还是不行(哭)
把PA其他部分做完回过头来尝试解决这个问题未果。不过既然argc能正常传递,想跳过商标页面还是能实现的。我们就用argc判断。
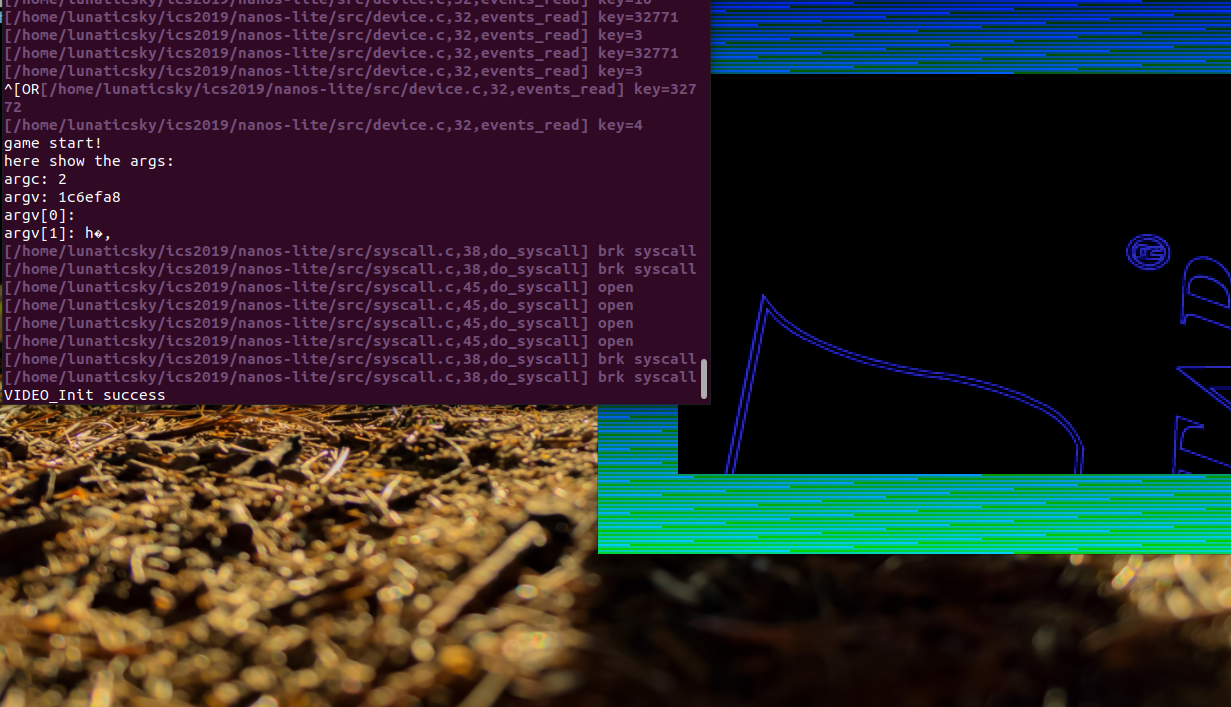
pal-main.c
int main(int argc, char *argv[])
{
Log("game start!");
Log("here show the args:");
Log("argc: %d", argc);
//log the address of argv
Log("argv: %x", argv);
for (int i = 0; i < argc; i++)
{
char* arg = argv[i];
Log("argv[%d]: %s", i, arg);
}
hal_init();
main_loop(argc);
return 0;
}main.c
if (argc!=2)
{
PAL_TrademarkScreen();
PAL_SplashScreen();
}可以看到直接跳过了加载动画。
阶段二
理解分页机制
理解分页细节
- 内存分页一页大小时 \(4 \mathrm{~KB}\) ,那么 \(4 \mathrm{~GB}\) 内存被分成 \(\frac{4 \mathrm{~GB}}{4 \mathrm{~KB}}=2^{20}\) 页,因此只需要 20 位寻址 \(2^{20}\) 页即可
- 因为虚拟地址到物理地址需要翻译,在访问CR3是并不知道映射规则(保存在页目录中,毕竟访 问CR3就是为了得到页目录) 那就肯定只能按照物理地址访问
- 页目录中会存储页表项 (用来寻址 \(2^{20}\) 页理论上只需要 \(3 \text B\) 但是为了方便一般页表项大小为 \(4 \mathrm{~B}\) ),那么每个进程都全部存储空间 (每一个页面) 都需要的页标项记录。于是需要空间存$4B × 2^{20} = 4 $存储,太大了,如果分级可以利用局部性原理有效减小页表项空间。
这三个问题其实在操作系统课上宫老师都讲过,\(4KB\)的页面大小设计也有巧合在里面。
空指针真的是空的吗
NULL 是一个标准规定的宏定义,用来表示空指针常量。在C中和早期的C++中它就是0
#define NULL (void*)0后来C++有了nullptr这个东西,不过与这个问题没啥关系。
下面的部分引自博客园
程序在使用的是系统给定的一个段,程序中的零值指针指向这个段的开端,为了保证NULL概念,系统为我们这个段的开头64K内存做了苛刻的规定,根据虚拟内存访问权限控制,我们程序中(低访问权限)访问要求高访问权限的这64K内存被视作是不容许的,所以会必然引发Access Volitation 错误,而这高权限的64K内存是一块保留内存(即不能被程序动态内存分配器分配,不能被访问,也不能被使用),就是简单的保留,不作任何使用。
因此空指针不是真的"空"。但NULL确实是0地址,它在虚拟地址空间中没有映射/有较高的访问权限。所以访问空指针的内容会爆段错误。
实现分页机制
先看一下加上HAS_VME是什么情况:
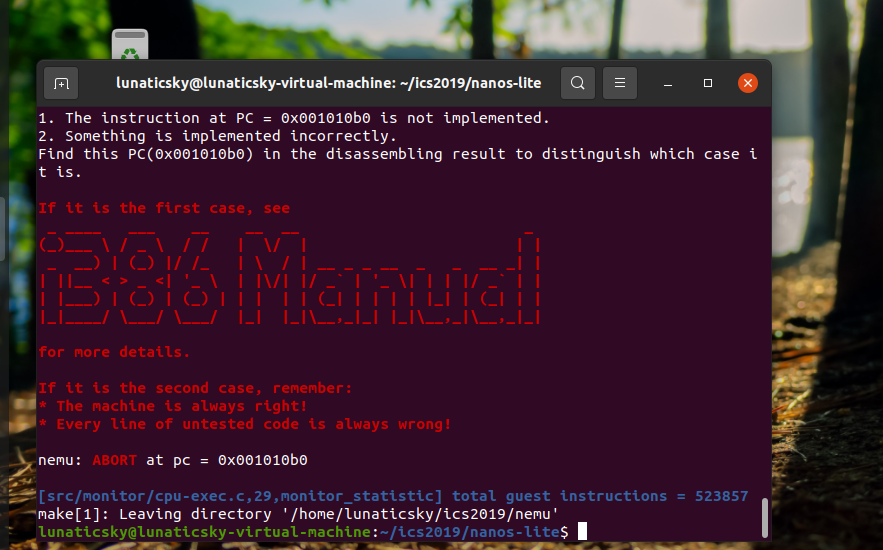
是这条指令:
1010b0: 0f 22 d8 mov %eax,%cr3
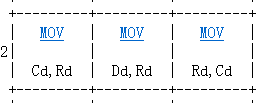
显然cr3的出现应当意识到与分页有关。而且是invalid opcode,那么就先要吧这个指令补上。这是一个两比特操作码的指令,在表的下面一部分
/* 0x20 */ IDEXW(G2E,mov_cr2r,4), EMPTY, IDEXW(E2G,mov_r2cr,4), EMPTY,查阅手册0x21也是与cr寄存器有关,一起补上。
make_EHelper(mov_r2cr) {
//TODO();
if (id_dest->reg==0) cpu.cr0.val=id_src->val;
else cpu.cr3.val=id_src->val;
print_asm("movl %%%s,%%cr%d", reg_name(id_src->reg, 4), id_dest->reg);
}
make_EHelper(mov_cr2r) {
//TODO();
if (id_src->reg==0) cpu.gpr[id_dest->reg]._32=cpu.cr0.val;
else cpu.gpr[id_dest->reg]._32=cpu.cr3.val;
print_asm("movl %%cr%d,%%%s", id_src->reg, reg_name(id_dest->reg, 4));
difftest_skip_ref();
}指令实现很简单,反正我们需要考虑的要么是cr0要么是cr3。
CPU_state也要补上这两个寄存器。寄存器的结构需#include "mmu.h",在nemu/src/isa/x86/include/isa/mmu.h里定义。
看上去好像能跑了?但还不是在虚拟地址上跑的嘛。因为目前isa_vaddr_read(),
isa_vaddr_write()并没有进行改动。这个就合并到下一节完成。
在分页机制上运行用户进程
我们先单独运行dummy(别忘记修改调度代码), 并先在
exit的实现中调用_halt()结束系统的运行。
先修改调度代码,省的后面忘了:
_Context *schedule(_Context *prev)
{
// save the context pointer
current->cp = prev;
// current = ((current == &pcb[0]) ? &pcb[1] : &pcb[0]);
current = &pcb[0];
// then return the new context
return current->cp;
}_Context *do_syscall(_Context *c)
case SYS_exit:
_halt(a[1]);需要按讲义中所讲取消原来进入开机菜单的选项,直接运行dummy。现在还没实现分页,可以看到也是能正常运行的。因为它只是调用了一下系统调用。
然后打开makefile.compile里的VME=enable之后,就发现寄喽。
我们首先需要在加载用户进程之前为其创建地址空间. 由于地址空间是进程相关的, 我们将
_AddressSpace结构体作为PCB的一部分. 这样以后, 我们只需要在context_uload()的开头调用_protect(), 就可以实现地址空间的创建。
目前这个地址空间除了内核映射之外就没有其它内容了。看代码确实如此。
int _protect(_AddressSpace *as) {
PDE *updir = (PDE*)(pgalloc_usr(1));
as->ptr = updir;
// map kernel space
for (int i = 0; i < NR_PDE; i ++) {
updir[i] = kpdirs[i];
}
return 0;
}
loader()要做的事情是, 获取程序的大小之后, 以页为单位进行加载:
- 申请一页空闲的物理页
- 通过
_map()把这一物理页映射到用户进程的虚拟地址空间中- 从文件中读入一页的内容到这一物理页上
这一部分实现需要谨慎一些,注意细节,写起来也让人挺抓狂的。不过还好没在这里卡住,反而下面犯了一个很蠢的错误。
Elf_Ehdr elf_header;
int fd = fs_open(filename, 0, 0);
Log("filename: %s, fd: %d", filename, fd);
size_t read_len = fs_read(fd, &elf_header, sizeof(Elf_Ehdr));
assert(read_len == sizeof(Elf_Ehdr));
Elf_Phdr elf_program_header[elf_header.e_phnum];
fs_lseek(fd, elf_header.e_phoff, SEEK_SET);
read_len = fs_read(fd, elf_program_header, sizeof(Elf_Phdr) * elf_header.e_phnum);
assert(read_len == sizeof(Elf_Phdr) * elf_header.e_phnum);
uintptr_t vaddr = 0;
size_t page_num;
void *pa;
for (int i = 0; i < elf_header.e_phnum; i++)
{
// only load PT_LOAD type
if (elf_program_header[i].p_type != PT_LOAD)
{
continue;
}
fs_lseek(fd, elf_program_header[i].p_offset, SEEK_SET);
vaddr = elf_program_header[i].p_vaddr;
page_num = (elf_program_header[i].p_filesz - 1) / PGSIZE + 1;
for (int j = 0; j < page_num; j++)
{
pa = new_page(1);
// check if the page is 4kb aligned
assert((vaddr & 0xfff) == 0);
_map(&pcb->as, (void *)vaddr, pa, 1);
if (j < page_num - 1)
{
fs_read(fd, pa, PGSIZE);
}
else
{
fs_read(fd, pa, elf_program_header[i].p_filesz % PGSIZE);
}
vaddr += PGSIZE;
}
assert(vaddr = page_num * PGSIZE + elf_program_header[i].p_vaddr);
// set the rest [Virtual Address + File Size, Virtual Address + Memory Size) to 0 turns to be a little complex
if (elf_program_header[i].p_filesz == elf_program_header[i].p_memsz)
{
pcb->max_brk = vaddr;
continue;
}
int zero_len = elf_program_header[i].p_memsz - elf_program_header[i].p_filesz;
if (zero_len < page_num * PGSIZE - elf_program_header[i].p_filesz)
{
memset((void *)(((uintptr_t)pa) + (elf_program_header[i].p_filesz - PGSIZE * (page_num - 1))), 0, zero_len);
}
else
{
// set the current page to 0
memset((void *)(((uintptr_t)pa) + (elf_program_header[i].p_filesz - PGSIZE * (page_num - 1))), 0, PGSIZE - elf_program_header[i].p_filesz % PGSIZE);
zero_len -= (PGSIZE - elf_program_header[i].p_filesz % PGSIZE);
// set the rest pages to 0 (we need to allocate new pages)
page_num = (zero_len - 1) / PGSIZE + 1;
for (int j = 0; j < page_num; j++)
{
pa = new_page(1);
assert((vaddr & 0xfff) == 0);
_map(&pcb->as, (void *)vaddr, pa, 1);
if (j < page_num - 1)
{
memset(pa, 0, PGSIZE);
}
else
{
memset(pa, 0, zero_len % PGSIZE);
}
vaddr += PGSIZE;
}
}
pcb->max_brk = vaddr;
}
fs_close(fd);
return elf_header.e_entry;你需要在AM中实现
_map()函数(在nexus-am/am/src/$ISA/nemu/src/vme.c中定义), 你可以通过as->ptr获取页目录的基地址. 若在映射过程中发现需要申请新的页表, 可以通过回调函数pgalloc_usr()向Nanos-lite获取一页空闲的物理页.
x86.h中有一些宏可以帮我们完成页面相关的地址转换,不用自己造轮子。
判断页面存在需要看最后一位是不是1,手册里说的很清楚。

int _map(_AddressSpace *as, void *va, void *pa, int prot)
{
// 来自讲义:将地址空间as中虚拟地址va所在的虚拟页, 以prot的权限映射到pa所在的物理页. 当prot中的present位为0时, 表示让va的映射无效
PDE *pdir = (PDE *)as->ptr;
PTE *ptab;
uint32_t pdir_idx = PDX(va);
uint32_t ptab_idx = PTX(va);
if (pdir[pdir_idx] &PTE_P)
{
// the page table is already exist
ptab = (PTE *)(PTE_ADDR(pdir[pdir_idx]));
}
else
{
// the page table is not exist
ptab = (PTE *)(PTE_ADDR(pgalloc_usr(1)));
// map the new-allocted page table to the pdir
pdir[pdir_idx] = (uintptr_t)ptab | PTE_P;
}
// map the page
ptab[ptab_idx] = PTE_ADDR(pa) |PTE_P;
return 0;
}为了让这一地址空间生效, 我们还需要将它落实到MMU中. 具体地, 我们希望在CTE恢复进程上下文的时候来切换地址空间. 为此, 我们需要将进程的地址空间描述符指针加入到上下文中. 框架代码已经实现了这一功能(见
nexus-am/am/include/arch/$ISA-nemu.h),
确实。
struct _Context {
struct _AddressSpace *as;
uintptr_t edi,esi, ebp, esp, ebx,edx,ecx,eax;
int irq;
uintptr_t eip, cs,eflags;
};但你还需要
- 修改
_ucontext()的实现, 在创建的用户进程上下文中设置地址空间相关的指针as- 在
__am_irq_handle()的开头调用__am_get_cur_as()(在nexus-am/am/src/$ISA/nemu/vme.c中定义), 来将当前的地址空间描述符指针保存到上下文中- 在
__am_irq_handle()返回前调用__am_switch()(nexus-am/am/src/$ISA/nemu/vme.c中定义) 来切换地址空间, 将调度目标进程的地址空间落实到MMU中
第一步,前面已经加过了。剩下的两步,照着做就好。
问题驱动。现在把isa_vaddr_read()和isa_vaddr_write()按照分页地址转换进行修改。写完loader和_map后已经算是对分页机制有较清晰的理解了,即便没有任何提示也基本完成的比较顺畅。
uint32_t page_translate(uint32_t addr)
{
// printf("addr:%x\n",addr);
uint32_t pdir = PDX(addr);
uint32_t ptab = PTX(addr);
uint32_t offset = OFF(addr);
// note that PDE is a struct, rather than a uint32_t in the nexus-am
PDE pde;
pde.val = paddr_read(PTE_ADDR(cpu.cr3.val) | (pdir << 2), 4);
// guarantee that the page table is present
assert(pde.present == 1);
PTE pte;
pte.val = paddr_read(PTE_ADDR(pde.val) | (ptab << 2), 4);
// guarantee that the page is present
if (pte.present == 0)
{
printf("addr:%x\n", addr);
}
assert(pte.present == 1);
uint32_t paddr = (PTE_ADDR(pte.val) | offset);
// printf("paddr:%x\n",paddr);
return paddr;
}
uint32_t isa_vaddr_read(vaddr_t addr, int len)
{
// return paddr_read(addr, len);
// now we need to handle the page mapping
if (cpu.cr0.paging == 0)
{
// no paging
return paddr_read(addr, len);
}
int start_page_num = addr / PAGE_SIZE;
int end_page_num = (addr + len - 1) / PAGE_SIZE;
if (start_page_num == end_page_num)
{
// the data is in one page
paddr_t paddr = page_translate(addr);
return paddr_read(paddr, len);
}
else
{
printf("the data is in two pages\n");
assert(0);
}
}
void isa_vaddr_write(vaddr_t addr, uint32_t data, int len)
{
if (cpu.cr0.paging == 0)
{
// no paging
paddr_write(addr, data, len);
return;
}
int start_page_num = addr / PAGE_SIZE;
int end_page_num = (addr + len - 1) / PAGE_SIZE;
if (start_page_num == end_page_num)
{
// the data is in one page
paddr_t paddr = page_translate(addr);
paddr_write(paddr, data, len);
}
else
{
printf("the data is in two pages\n");
assert(0);
}
}
改正之后能够在分页机制上Hit good trap。
在分页机制上运行仙剑奇侠传
现在用户进程运行在分页机制之上, 我们还需要在
mm_brk()中把新申请的堆区映射到虚拟地址空间中, 这样才能保证运行在分页机制上的用户进程可以正确地访问新申请的堆区.
如文中所述:
我们可以不实现堆区的回收功能, 而是只为当前新program break超过
max_brk部分的虚拟地址空间分配物理页.
据此实现:
int mm_brk(uintptr_t brk, intptr_t increment) {
if (brk+increment>current->max_brk)
{
int new_pgnum=((brk+increment-current->max_brk)+0xfff)/PGSIZE;
for (int i=new_pgnum-1;i>=0;--i)
{
void *pa=new_page(1);
_map(&(current->as),(void*)(current->max_brk),pa,1);
current->max_brk+=PGSIZE;
}
}
return 0;
}new_pgnum计算了需要分配的页面个数。看上去很简单粗暴。为什么不用考虑页面对齐问题?因为我实现的loader加载的时候分配的max_brk值是页面对齐的,这里更新的时候current->max_brk+=PGSIZE;也是页面对齐的,因此就不需要考虑brk+increment
与 max_brk在同一页面上的问题。
我们这是在mm中,要想访问当前进程的max_brk需要从进程控制块中获取。因此需要
#include "proc.h"
extern PCB *current;别忘了在系统调用里注册新实现的max_brk,一开始实现完了忘了注册,缺一堆页,排查了一个多小时发现是忘了在系统调用更新。
_Context *do_syscall(_Context *c):
case SYS_brk:
{
Log("brk syscall");
//_end=*((char*)c->GPR2);
mm_brk((uintptr_t)a[1],(intptr_t)a[2]);
c->GPRx=0;
break;
}好了,我们跑一下仙剑奇侠传看看:
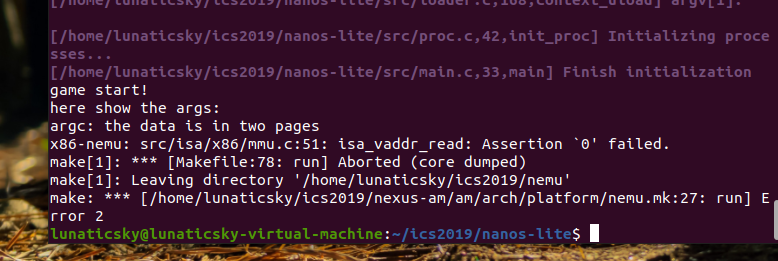
emm。确实如讲义所说。我们现在不得不处理数据跨页的问题了。
跨页的思路也不难,在
vaddr_read中将两次读取的字节进行整合,在
vaddr_write 中将需要写入
的字节进行拆分并分别写入两个页面即可。
read的处理如下:write是完全类似的。
else
{
// printf("the data is in two pages\n");
// assert(0);
// the data is in two pages
int first_page_len = PAGE_SIZE - OFF(addr);
// printf("crossong page data addr:%x\n", addr);
paddr_t paddr = page_translate(addr);
uint32_t first_page_data = paddr_read(paddr, first_page_len);
paddr = page_translate(addr + first_page_len);
uint32_t second_page_data = paddr_read(paddr, len - first_page_len);
return (second_page_data << (first_page_len * 8)) + first_page_data;
}else
{
// printf("the data is in two pages\n");
// assert(0);
// the data is in two pages
int first_page_len = PAGE_SIZE - OFF(addr);
// printf("crossong page data addr:%x\n", addr);
paddr_t paddr = page_translate(addr);
paddr_write(paddr, data & ((1 << (first_page_len * 8)) - 1), first_page_len);
paddr = page_translate(addr + first_page_len);
paddr_write(paddr, data >> (first_page_len * 8), len - first_page_len);
}
支持虚存管理的多道程序
这次只需要把调度代码改回去就可以了,不需要做额外的事情。
阶段三
实现抢占多任务
时钟中断通过
nemu/src/device/timer.c中的timer_intr()触发, 每10ms触发一次. 触发后, 会调用dev_raise_intr()函数(在nemu/src/device/intr.c中定义). 你需要:
- 在
cpu结构体中添加一个bool成员INTR.- 在
dev_raise_intr()中将INTR引脚设置为高电平.- 在
exec_once()的末尾添加轮询INTR引脚的代码, 每次执行完一条指令就查看是否有硬件中断到来:
这三步照着做即可。
- 实现
isa_query_intr()函数(在nemu/src/isa/$ISA/intr.c中定义):
注意Interrupt Enable Flag ,等于1接收中断响应。
bool isa_query_intr(void) {
if (cpu.INTR==true&&cpu.eflags.IF==1)
{
cpu.INTR=false;
raise_intr(IRQ_TIMER,cpu.pc);
return true;
}
return false;
}
- 修改
raise_intr()中的代码, 让处理器进入关中断状态:
void raise_intr(uint32_t NO, vaddr_t ret_addr)
{
/* TODO: Trigger an interrupt/exception with ``NO''.
* That is, use ``NO'' to index the IDT.
*/
// step1
rtl_push(&cpu.eflags.val);
rtl_push(&cpu.cs);
rtl_push(&ret_addr);
cpu.eflags.IF = 0;
// step2
uint32_t gate_addr = cpu.idtr.base, len = cpu.idtr.limit;
if (len <= NO)
{
printf("the number is larger than the length of IDT!\n");
assert(0);
}
//step3
uint32_t val_l, val_h, p;
val_l = vaddr_read(gate_addr + NO * 8, 2);
val_h = vaddr_read(gate_addr + NO * 8 + 6, 2);
p = vaddr_read(gate_addr + NO * 8 + 5, 1) >> 7;
//actually no need to check p for NEMU, but we can do it.
if (!p)
{
printf("The gatedesc is not allowed!");
assert(0);
}
//step4
//using rtl api
vaddr_t goal = (val_h << 16) + val_l;
rtl_j(goal);
}在软件上, 你还需要:
- 在CTE中添加时钟中断的支持, 将时钟中断打包成
_EVENT_IRQ_TIMER事件.- Nanos-lite收到
_EVENT_IRQ_TIMER事件之后, 调用_yield()来强制当前进程让出CPU, 同时也可以去掉我们之前在设备访问中插入的_yield()了.- 为了可以让处理器在运行用户进程的时候响应时钟中断, 你还需要修改
_ucontext()的代码, 在构造上下文的时候, 设置正确中断状态, 使得将来返回到用户进程后CPU处于开中断状态.
这三条也是照着做即可。
最后讲义中没提到的,是在__am_irq_handle中注册_EVENT_IRQ_TIMER。
case 32:
ev.event = _EVENT_IRQ_TIMER;
break;可以看到每隔一段时间都触发一次时钟中断事件。
展示你的计算机系统
我们可以在Nanos-lite的
events_read()函数中让F1,F2,F3这3个按键来和3个前台程序绑定, 例如, 一开始是仙剑奇侠传和hello程序分时运行, 按下F3之后, 就变成slider和hello程序分时运行. 如果你没有实现Navy-apps之上的AM, 可以加载3份仙剑奇侠传, 让它们分别读取不同的存档进行游戏.
if (key & 0x8000)
{
//0x8002 to 0x8004 are F1 to F3
if (key>=0x8002&&key<=0x8004) change_gcb(key-0x8001);
sprintf((char *)buf, "kd %s\n", keyname[key & 0x7fff]);
}amdev.h里有张键位表,可以参考。
change_gcb需要添加外部引用。在proc.c定义:
uint32_t fg_pcb;
void change_gcb(uint32_t id) { fg_pcb = id; }修改schedule:
uint32_t now_id = 0;
_Context *schedule(_Context *prev)
{
// save the context pointer
current->cp = prev;
if (now_id != fg_pcb)
{
now_id = fg_pcb;
current = &pcb[fg_pcb];
}
else
{
now_id = 0;
current = &pcb[0];
}
// current = ((current == &pcb[0]) ? &pcb[1] : &pcb[0]);
// current = &pcb[0];
// then return the new context
return current->cp;
}为了更清晰的验证实现的效果,我将hello的输出注释掉了,并添加了键盘事件的Log。可以看到按F1-F3键的时候游戏会重新进入,hello也在一直运行。当然如果一直按的和上一次相同的按键不会有变化。
必答题
hello程序是什么, 它从而何来, 要到哪里去
hello 程序在磁盘上,hello.c 被编译成 ELF 文件后,位于 ramdisk 中。当用户运行该程序时,通过 naive_uload 函数读入指定的内存并放在正确的位置。加载完成后,操作系统从其 ELF 信息中获取到程序入口地址,通过上下文切换从入口地址处继续执行,hello 程序便获取到 CPU 的控制权开始执行指令。
对于字符串在终端的显示,首先调用printf
等库函数,然后通过 SYS_write
系统调用来输出字符,系统调用通过调用外设的驱动程序最终将内容在外设中表现出来,程序执行完毕后操作系统会回收其内存空间。
上述只是大致的流程,展开来讲的话每一句话都可以拓展很多。由于时间有限这里就不展开了。
上下文切换的具体过程
首先回顾PA3的选做题
AM究竟给程序提供了多大的栈空间呢?
观察nexus-am/am/src/x86/nemu/boot/loader.ld这个链接脚本可以发现,其中定义了一个符号_stack_pointer
而根据AM启动客户程序的流程可知,在nexus-am/am/src/x86/nemu/boot/start.S中的_start:中将会执行mov $_stack_pointer, %esp,以此初始化栈指针。又注意到_stack_top符号的地址与之相差0x8000,因此可以回答AM中程序的栈空间大小为0x8000字节。
当然在在本次实验中也可以查看PCB的结构:
#define STACK_SIZE (8 * PGSIZE)
typedef union {
uint8_t stack[STACK_SIZE] PG_ALIGN;
struct {
_Context *cp;
_AddressSpace as;
// we do not free memory, so use `max_brk' to determine when to call _map()
uintptr_t max_brk;
};
} PCB;STACK_SIZE (8 * PGSIZE)=8*4096=32768=0x8000,和从汇编中的得到的结果是一致的。
在这次实验指导书中也有说明:
代码为每一个进程分配了一个32KB的堆栈, 已经足够使用了, 不会出现栈溢出导致UB.
结合PA3的前两个必答题,在此以内核进程hello为例,将上下文切换的整个细节总结如下:

分时多任务的具体过程
请结合代码, 解释分页机制和硬件中断是如何支撑仙剑奇侠传和hello程序在我们的计算机系统(Nanos-lite, AM, NEMU)中分时运行的.
分页机制由 Nanos-lite、AM 和 NEMU 配合实现。
首先,NEMU 提供 CR0 与 CR3 寄存器来辅助实现分页机制,CR0用于开启分页,CR3 记录页表基地址。随后,MMU 进行分页地址的转换,在代码中表现为 NEMU 的
vaddr_read()与vaddr_write()。当启动一个用户进程后,Nanos-lite会在开头调用
_protect(), 它是AM中的功能,可以实现地址空间的创建,并且将内核空间映射到用户空间。之后进行loader(),在loader函数中与之前不同是,操作系统使用分页机制对其进行存储和加载,通过 new_page 获得新的物理页,并用到AM中_map以建立虚拟地址与物理地址的映射关系,退出后调用am中的_ucontext,在栈上创建必要的上下文信息和参数信息,而分页机制则保证了进程在对应虚拟地址存取信息时, 在NEMU中能够通过page_translate()函数等完成到物理地址的转换,从而获得正确的信息。之后在NEMU中运行时,每10ms在
timer_intr()触发一次时钟中断,此时NEMU检测到isa_query_intr()为true,同时也会在该函数中调用raise_intr,为中断事件做准备并产生异常号。而操作系统接受到_EVENT_IRQ_TIMER后调用_yield()强行暂停该进程,最后在schedule中更换当前进程,通过AM 的_switch()切换进程的虚拟内存空间, 并将进程的上下文传递给 AM,AM 的asm_trap()恢复这一现场。NEMU 执行下 一条指令时,便开始新进程的运行。完成进程转换,如此反复形成分时运行。